
C/C++内存知识点
内存
一、概念
1.1、内存地址空间
| 程序地址空间 | Stack | 高地址 |
|---|---|---|
| 向下成长 ↓ | ||
| 向上成长 ↑ | ||
| Heap | 低地址 |
1.2、C++ 内存上的布局以及存取时间主要的额外负担是由 virtual 引起的
virtual function 机制用以支持一个有效率的执行期绑定(runtime binding)。
虚继承 virtual base class 用以实现多次出现在继承体系中的 base class,有一个单一而被共享的实体。
1.3、C++ 内存布局
堆、栈、自由存储区、全局/静态存储区、常量存储区
1.4、自由存储区和堆
一般认为自由存储区与堆的划分标准是申请和释放内存是使用的 new/delete 还是 malloc/free。C++ 标准并没有给出 new/delete 应该如何实现,但很多编译器的 new/delete 都是以 malloc/free 为基础来实现的。从技术上来说,堆(heap)是 C 语言和操作系统的术语,堆是操作系统所维护的一块特殊内存,它提供了动态分配的功能,使用 malloc()、free() 来申请/释放内存。而自由存储是 C++ 中通过 new 和 delete 动态分配和释放对象的抽象概念。基本上,所有的 C++ 编译器默认使用堆来实现自由存储。也就是说,默认的全局运算符 new 和 delete 也许会使用 malloc 和 free 的方式申请和释放存储空间,也就是说自由存储区就位于堆上。但程序员也可以通过重载操作符,改用其他内存来实现自由存储,例如全局变量做的对象池,这时自由存储区就不位于堆上了。
自由存储区和堆的区别是:堆是操作系统维护的一块内存,是一个物理概念,而自由存储是 C++ 中通过 new 与 delete 动态分配和释放的对象的存储区,是一个逻辑概念。
1.5、动态内存分配问题
内存分配有静态分配和动态分配两种。静态分配在程序编译链接时分配的大小和使用寿命就已经确定,而应用上要求操作系统可以提供给进程运行时申请和释放任意大小内存的功能,这就是内存的动态分配。
因此动态分配将不可避免会产生内存碎片的问题,那么什么是内存碎片?内存碎片即“碎片的内存”,描述一个系统中所有不可用的空闲内存,这些碎片之所以不能被使用,是因为负责动态分配内存的分配算法使得这些空闲的内存无法使用,这一问题的发生,原因在于这些空闲内存以较小且不连续方式出现在不同的位置。因此这个问题或多或少取决于内存管理算法的实现上。
1.6、为什么会产生这些小且不连续的空闲内存碎片呢?
实际上这些空闲内存碎片存在的方式有两种:
内部碎片
内部碎片的产生:因为所有的内存分配必须起始于可被 4、8 或 16 整除(视处理器体系结构而定)的地址或者因为 MMU 的分页机制的限制,决定内存分配算法仅能把预定大小的内存块分配给客户。假设当某个客户请求一个 43 字节的内存块时,因为没有适合大小的内存,所以它可能会获得 44 字节、48 字节等稍大一点的字节内存块,因此由所需大小四舍五入而产生的多余空间就叫内部碎片。外部碎片
外部碎片的产生:频繁的分配与回收物理页面会导致大量的、连续且小的页面块夹杂在已分配的页面中间,就会产生外部碎片。假设有一块一共有 100 个单位的连续空闲内存空间,范围是 0 ~ 99。如果你从中申请一块内存,如 10 个单位,那么申请出来的内存块就为 0 ~ 9 区间。这时候你继续申请一块内存,比如说5个单位大,第二块得到的内存块就应该为 10 ~ 14 区间。如果你把第一块内存块释放,然后再申请一块大于 10 个单位的内存块,比如说 20 个单位。因为刚被释放的内存块不能满足新的请求,所以只能从 15 开始分配出 20 个单位的内存块。现在整个内存空间的状态是 0 ~ 9 空闲,10 ~ 14 被占用,15 ~ 24 被占用,25 ~ 99 空闲。其中 0 ~ 9 就是一个内存碎片了。如果 10 ~ 14 一直被占用,而以后申请的空间都大于 10 个单位,那么 0 ~ 9 就永远用不上了,变成外部碎片。
1.7、系统内存回收机制问题
内存碎片是一个系统问题,反复的 malloc 和 free,而 free 后的内存又不能马上被系统回收利用。这个与系统对内存的回收机制有关。
内存碎片带来的问题:大量的内存碎片会使系统缓慢,原因在于虚拟内存的使用会使内存与硬盘之间的数据交换成为系统缓慢的根源,最终造成内存的枯竭。
1.8、如何避免内存碎片的产生
1、少用动态内存分配的函数(尽量使用栈空间)
2、分配内存和释放内存尽量在同一个函数中
3、尽量一次性申请较大的内存(2的指数次幂大小的内存空间),而不要反复申请小内存(少进行内存的分割)
4、使用内存池来减少使用堆内存引起的内存碎片
1.9、memcpy 与 memmove 的区别
memcpy 和 memmove 都是 C 语言的库函数,相比于 strcpy 和 strncpy 只能拷贝字符串数组,memcpy 与 memmove 可以拷贝其它类型的数组。
1 | void *memcpy(void *restrict s1, const void *restrict s2, size_t n); |
这两个函数都是将 s2 指向位置的 n 字节数据拷贝到 s1 指向的位置,区别就在于关键字 restrict,memcpy 假定两块内存区域没有数据重叠,而 memmove 没有这个前提条件。如果复制的两个区域存在重叠时使用 memcpy,其结果是不可预知的,有可能成功也有可能失败的,所以如果使用了 memcpy,程序员自身必须确保两块内存没有重叠部分。
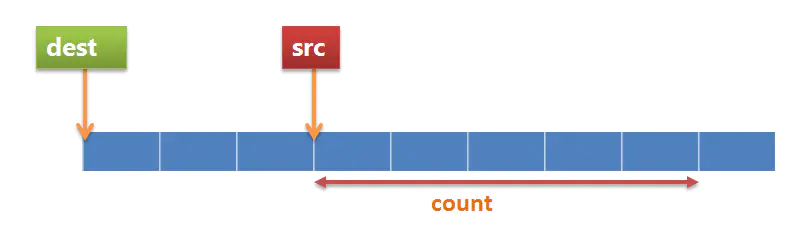
正常情况下,即使内容有重叠,src 的内容也可以正确地被拷贝到了 dest 指向的空间。
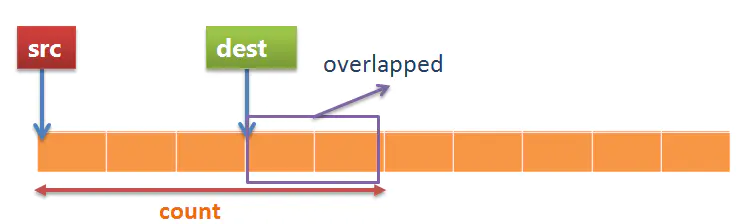
这种情况下,src 的地址小于 dest 的地址,拷贝前 3 个字节没问题,但是拷贝第 4,5 个字节时,原有的内容已经被 src 拷贝过来的字符覆盖了,所以已经丢失原来 src 的内容,这很明显就是问题所在。
memcpy 的实现
1 |
|
memmove 的实现
memmove 会对拷贝的数据作检查,确保内存没有覆盖,如果发现会覆盖数据,简单的实现是调转开始拷贝的位置,从尾部开始拷贝:
1 |
|
这里 __np_anyptrlt 是一个简单的宏,用于结合拷贝的长度检测 dest 与 src 的位置,如果 dest 和 src 指向同样的对象,且 src 比dest 地址小,就需要从尾部开始拷贝,否则就和 memcpy 处理相同。但是实际在 C99 实现中,是将内容拷贝到临时空间,再拷贝到目标地址中:
1 |
|
由此可见 memcpy 的速度比 memmove 快一点,如果使用者可以确定内存不会重叠,则可以选用 memcpy,否则 memmove 更安全一些。另外一个提示是第三个参数是拷贝的长度,如果你是拷贝 10 个 double 类型的数值,要写成 sizeof(double)*10,而不仅仅是 10。
实现 memmove 有两个要点:
(1)从 src 指向的内存拷贝 count 个字节到 dst 指向的内存中。
(2)处理 src 和 dst 有重叠的情况,这是和 memcpy 不一样的地方。
1 | void * __cdecl memmove ( |
1.10、为什么 new[]/delete[] 需要记录对象个数?
- 对于有 non-trivial destructor 的 class T,现在通常的 C++ 实现会在 new[] 的时候多分配 sizeof(size_t) 字节用于保存数组大小,在 delete[] 的时候会依次逆序调用数组中各对象的析构函数。有的文献管这多分配的几个字节叫 new cookie (Itanium C++ ABI)。
- new/malloc 会记录分配的内存的长度,delete/free 的时候无需指定长度,只要传入首地址即可。
那或许有人会问,既然根据数组首地址就能知道分配了多少字节内存,那为什么 new[] 还需要再保存对象的数目?这不是多余吗?直接用内存长度 / sizeof(T) 不就可以算出需要析构多少个对象了?
原因很简单:
内存长度 / sizeof(T) >= 对象个数
因为 new / malloc 在分配内存的时候会 round up 到某个数的倍数(8 或 16 等,跟 malloc 具体实现有关),即内存长度 = round_up(sizeof(T) * 对象个数),那么反过来我们就不能用内存长度算出对象个数了,必须单独保存对象个数。
假如不采用 new cookie,如果 sizeof(Foo) == 4,那么 Foo* p = new Foo[28]; 会分配 112 字节来构造 28 个对象,但实际会从 libc 拿到 116 字节,那么 delete[] p; 会析构 116/4 = 29 个对象,这就有大问题了。
因此,通常的 C++ 实现在必要时会在 new[] 的时候多分配 sizeof(size_t) 字节用于保存对象数目,而不是让 delete[] 依靠内存大小来算出需要析构多少个对象。
二、内存分配方式
C++ 中内存分配十分重要,并且容易造成内存泄露等等问题,之前只是知道 new 和 delete 底层调用的是 malloc 和 free,下面就深入分析一下 new 和 delete 的执行步骤以及自定义内存池。
C++ 中内存分配的层次,其中 C++ Library 分配器就是 STL 中的内存分配结构,将 new/malloc 以及 delete/free 进一步封装,减少 new/malloc 的次数,做成一个内存池。
2.1、malloc/free 函数
C 语言中的内存分配函数,速度很快,返回的是 void* 类型的指针
1 | void* p1 = malloc(512); |
2.2、new/delete 函数
new 动作包含两个动作:
- 开辟空间
- 构造对象
delete 动作包含两个动作:
- 析构对象
- 释放空间
1 | complex<int>* p2 = new complex<int>; |
2.3、array new/delete 函数
如果使用 array new,则必须使用 array delete 相对应,否则会出现内存泄露的现象。
1 | Complex *pca = new Complex[3]; //唤起三次ctor |
2.4、::operator new/delete 函数**
这是一个全局函数,在调用 new 函数的时候,首先编译器会先调用这个函数,并且此函数是唯一可以重载的,使用自己定义的 ::operator new 函数(但是一般不会重载全局的 ::operator new/delete 函数),而是重载类中对应的 operator new/delete 函数,这样就不会影响全局的 ::operator new/delete 函数。
::operator new 返回的也是 void* 类型的指针
1 | void* a = ::operator new (sizeof(int)); |
2.5、new 整体流程
1 | Complex *pc = new Complex(1, 2); |
上述程序会被编译器转换为:
1 | Complex *pc; |
我们知道对象的指针是不可以直接调用构造函数的,但是编译器可以直接调用,此为编译器的特权。
首先 new 会调用 operator new 函数,如果我们不重载 operator new 函数的话,operator new 函数中调用的即为 malloc 函数,然后进行强制类型转换,以及对象的构造。
2.6、delete 整体流程
1 | delete pc; |
上述程序会被编译器转换为:
1 | pc->~Complex(); //先析构 |
没有重载的全局 operator delete 函数直接调用 free 函数。
2.7、operator new/delete 的重载
1 |
|
三、如何避免内存泄露
近年来,讨论 C++ 的人越来越少了,一方面是由于像 Python,Go 等优秀的语言的流行,另一方面,大家也越来越明白一个道理,并不是所有的场景都必须使用 C++ 进行开发。Python 可以应付大部分对性能要求不高的场景,Go 可以应付大部分对并发要求较高的场景,而由于 C++ 的复杂性,只有在对性能极其苛刻的场景下,才会考虑使用。
那么到底多苛刻算是苛刻呢?Go 自带内存管理,也就是 GC 功能,经过多年的优化,在 Go 中每次 GC 可能会引入 500us 的 STW 延迟。

也就是说,如果你的应用场景可以容忍不定期的 500us 的延迟,那么用 Go 都是没有问题的。如果你无法容忍 500us 的延迟,那么带 GC 功能的语言就基本无法使用了,只能选择自己管理内存的语言,例如 C++。那么由手动管理内存而带来的编程复杂度也就随之而来了。
作为 C++ 程序员,内存泄露始终是悬在头上的一颗炸弹。在过去几年的 C++ 开发过程中,由于我们采用了一些技术,我们的程序发生内存泄露的情况屈指可数。今天就在这里向大家做一个简单的介绍。
3.1、内存是如何泄露的
在 C++ 程序中,主要涉及到的内存就是『栈』和『堆』(其他部分不在本文中介绍了)。
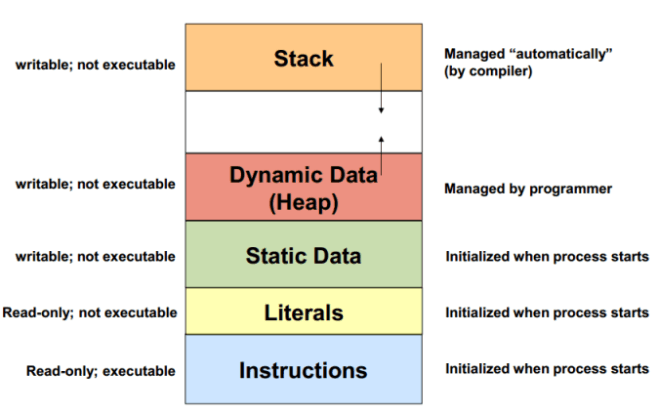
通常来说,一个线程的栈内存是有限的,通常来说是 8M 左右(取决于运行的环境)。栈上的内存通常是由编译器来自动管理的。当在栈上分配一个新的变量时,或进入一个函数时,栈的指针会下移,相当于在栈上分配了一块内存。我们把一个变量分配在栈上,也就是利用了栈上的内存空间。当这个变量的生命周期结束时,栈的指针会上移,相同于回收了内存。
由于栈上的内存的分配和回收都是由编译器控制的,所以在栈上是不会发生内存泄露的,只会发生栈溢出(Stack Overflow),也就是分配的空间超过了规定的栈大小。
而堆上的内存是由程序直接控制的,程序可以通过 malloc/free 或 new/delete 来分配和回收内存,如果程序中通过 malloc/new 分配了一块内存,但忘记使用 free/delete 来回收内存,就发生了内存泄露。
经验 #1:尽量避免在堆上分配内存
既然只有堆上会发生内存泄露,那第一原则肯定是避免在堆上面进行内存分配,尽可能的使用栈上的内存,由编译器进行分配和回收,这样当然就不会有内存泄露了。
然而,只在栈上分配内存,在有 IO 的情况下是存在一定局限性的。
举个例子,为了完成一个请求,我们通常会为这个请求构造一个 Context 对象,用于描述和这个请求有关的一些上下文。例如下面一段代码:
1 | void Foo(Reuqest* req) { |
如果 HandleRequest 是一个同步函数,当这个函数返回时,请求就可以被处理完成,那么显然 ctx 是可以被分配在栈上的。
但如果 HandleRequest 是一个异步函数,例如:
1 | void HandleRequest(RequestContext* ctx, Callback cb); |
那么显然,ctx 是不能被分配在栈上的,因为如果 ctx 被分配在栈上,那么当 Foo 函数退出后,ctx 对象的生命周期也就结束了。而 FooCB 中显然会使用到 ctx 对象。
1 | void HandleRequest(RequestContext* ctx, Callback cb); |
在这种情况下,如果忘记在 FooCB 中调用 delete ctx,则就会触发内存泄露。尽管我们可以借助一些静态检查工具对代码进行检查,但往往异步程序的逻辑是极其复杂的,一个请求的生命周期中,也需要进行大量的内存分配操作,静态检查工具往往无法发现所有的内存泄露情况。
那么怎么才能避免这种情况的产生呢?引入智能指针显然是一种可行的方法,但引入 shared_ptr 往往引入了额外的性能开销,并不十分理想。
经验 #2:使用 Arena
Arena 是一种统一化管理内存生命周期的方法。所有需要在堆上分配的内存,不通过 malloc/new,而是通过 Arena 的 CreateObject 接口。同时,不需要手动的执行 free/delete,而是在 Arena 被销毁的时候,统一释放所有通过 Arena 对象申请的内存。所以,只需要确保 Arena 对象一定被销毁就可以了,而不用再关心其他对象是否有漏掉的 free/delete。这样显然降低了内存管理的复杂度。
此外,我们还可以将 Arena 的生命周期与 Request 的生命周期绑定,一个 Request 生命周期内的所有内存分配都通过 Arena 完成。这样的好处是,我们可以在构造 Arena 的时候,大概预估出处理完成这个 Request 会消耗多少内存,并提前将会使用到的内存一次性的申请完成,从而减少了在处理一个请求的过程中,分配和回收内存的次数,从而优化了性能。
经验 #3:使用 Coroutine
Coroutine 相信大家并不陌生,那 Coroutine 的本质是什么?我认为 Coroutine 的本质,是使得一个线程中可以存在多个上下文,并可以由用户控制在多个上下文之间进行切换。而在上下文中,一个重要的组成部分,就是栈指针。使用 Coroutine,意味着我们在一个线程中,可以创造(或模拟)多个栈。
有了多个栈,意味着当我们要做一个异步处理时,不需要释放当前栈上的内存,而只需要切换到另一个栈上,就可以继续做其他的事情了,当异步处理完成时,可以再切换回到这个栈上,将这个请求处理完成。
还是以刚才的代码为示例:
1 | void Foo(Reuqest* req) { |
这里的精髓在于,尽管 Coroutine::Self()->Yield() 被调用时,程序可以跳出 HandleRequest 函数去执行其他代码逻辑,但当前的栈却被保存了下来,所以 ctx 对象是安全的,并没有被释放。
这样一来,我们就可以完全抛弃在堆上申请内存,只是用栈上的内存,就可以完成请求的处理,完全不用考虑内存泄露的问题。然而这种假设过于理想,由于在栈上申请内存存在一定的限制,例如栈大小的限制,以及需要在编译是知道分配内存的大小,所以在实际场景中,我们通常会结合使用 Arena 和 Coroutine 两种技术一起使用。
有人可能会提到,想要多个栈用多个线程不就可以了?然而用多线程实现多个栈的问题在于,线程的创建和销毁的开销极大,且线程间切换,也就是在栈之间进行切换的代销需要经过操作系统,这个开销也是极大的。所以想用线程模拟多个栈的想法在实际场景中是走不通的。
这里需要强调一下,Coroutine 确实会带来一定的性能开销,通常 Coroutine 切换的开销在 20ns 以内,然而我们依然在对性能要求很苛刻的场景使用 Coroutine,一方面是因为 20ns 的性能开销是相对很小的,另一方面是因为 Coroutine 极大的降低了异步编程的复杂度,降低了内存泄露的可能性,使得编写异步程序像编写同步程序一样简单,降低了程序员心智的开销。
经验 #4:善用 RAII
尽管在有些场景使用了 Coroutine,但还是可能会有在堆上申请内存的需要,而此时有可能 Arena 也并不适用。在这种情况下,善用 RAII(Resource Acquisition Is Initialization)思想会帮助我们解决很多问题。
简单来说,RAII 可以帮助我们将管理堆上的内存,简化为管理栈上的内存,从而达到利用编译器自动解决内存回收问题的效果。此外,RAII 可以简化的还不仅仅是内存管理,还可以简化对资源的管理,例如 fd,锁,引用计数等等。
当我们需要在堆上分配内存时,我们可以同时在栈上面分配一个对象,让栈上面的对象对堆上面的对象进行封装,同时通过在栈对象的析构函数中释放堆内存的方式,将栈对象的生命周期和堆内存进行绑定。
unique_ptr 就是一种很典型的例子。然而 unique_ptr 管理的对象类型只能是指针,对于其他的资源,例如 fd,我们可以通过将 fd 封装成另外一个 FileHandle 对象的方式管理,也可以采用一些更通用的方式。例如,在我们内部的 C++ 基础库中实现了 Defer 类,想法类似于 Go 中 defer。
1 | void Foo() { |
经验 #5:便于 Debug
在特定的情况下,我们难免还是要手动管理堆上的内存。然而当我们面临一个正在发生内存泄露线上程序时,我们应该怎么处理呢?
当然不是简单的『重启大法好』,毕竟重启后还是可能会产生泄露,而且最宝贵的现场也被破坏了。最佳的方式,还是利用现场进行 Debug,这就要求程序具有便于 Debug 的能力。
这里不得不提到一个经典而强大的工具 gperftools。gperftools 是 google 开源的一个工具集,包含了 tcmalloc,heap profiler,heap checker,cpu profiler 等等。gperftools 的作者之一,就是大名鼎鼎的 Sanjay Ghemawat,没错,就是与 Jeff Dean 齐名,并和他一起写 MapReduce 的那个 Sanjay。
gperftools 的一些经典用法,我们就不在这里进行介绍了,大家可以自行查看文档。而使用 gperftools 可以在不重启程序的情况下,进行内存泄露检查,这个恐怕是很少有人了解。
实际上我们 Release 版本的 C++ 程序可执行文件在编译时全部都链接了 gperftools。在 gperftools 的 heap profiler 中,提供了 HeapProfilerStart 和 HeapProfilerStop 的接口,使得我们可以在运行时启动和停止 heap profiler。同时,我们每个程序都暴露了 RPC 接口,用于接收控制命令和调试命令。在调试命令中,我们就增加了调用 HeapProfilerStart 和 HeapProfilerStop 的命令。由于链接了 tcmalloc,所以 tcmalloc 可以获取所有内存分配和回收的信息。当 heap profiler 启动后,就会定期的将程序内存分配和回收的行为 dump 到一个临时文件中。
当程序运行一段时间后,你将得到一组 heap profile 文件
1 | profile.0001.heap |
每个 profile 文件中都包含了一段时间内,程序中内存分配和回收的记录。如果想要找到内存泄露的线索,可以通过使用
1 | pprof --base=profile.0001.heap /usr/bin/xxx profile.0100.heap --text |
来进行查看,也可以生成 pdf 文件,会更直观一些。
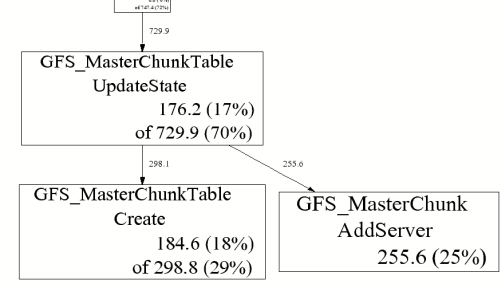
这样一来,我们就可以很方便的对线上程序的内存泄露进行 Debug 了。
总结
C++ 可谓是最复杂、最灵活的语言,也最容易给大家带来困扰。如果想要用好 C++,团队必须保持比较成熟的心态,团队成员必须愿意按照一定的规则来使用 C++,而不是任性的随意发挥。这样大家才能把更多精力放在业务本身,而不是编程语言的特性上。
参考原文:
1、memcpy与memmove的区别
2、C++ 如何避免内存泄漏
- 本文标题:C/C++内存知识点
- 本文作者:beyondhxl
- 本文链接:https://www.beyondhxl.com/post/dda3c6bd.html
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!






