
C++游戏服务器知识点散记
C++ 游戏服务器知识点零散记录
Static
1、声明为 static 的对象
2、global scope
3、namespace scope
多态
非自然多态 unnatural polymorphism
对象涉及多重继承或虚拟继承的基类,会拥有多个地址
C++ 以下列方法支持多态:
1、隐式的转化
把一个 derived class 指针转化为一个指向其 public base type 的指针
2、经由 virtual function 机制
3、经由 dynamic-cast 和 typeid 运算法
多态的主要用途
经由一个共同的接口来影响类型的封装,这个接口通常被定义在一个抽象的 base class 中。这个接口是以 virtual function 机制引发的,它可以在执行期根据 object 的真正类型解析出到底是哪一个函数实体被调用。
抽象混合式基类 abstract base class
不能被实例化的 base class 至少有一个纯虚函数
转型
1、dynamic_cast 只适用于那种”所指对象至少有一个虚函数”
C++ 隐式类型转换和关键字 explicit
1、explicit 制止单一参数的 constructor 被当做一个 conversion 运算符
2、conversion 运算符即类型转换运算符,这是类的一种特殊成员函数,它负责将一个类类型的值转换成其他类型,一般形式为:operator type() const,其中 type 表示被转换成的某种类型。
3、《C++ Primer》中讲到了一个规定:如果构造函数只接受一个实参,则它实际上定义了转换为此类类型的隐式转换机制(关键字 explicit 出现的原因就是在 C++ 这个规定的基础上)。
1 | class Test |
explicit 构造函数只能用于直接初始化,不能用于拷贝形式的初始化过程。
编译
Java 生成的是字节码,没有链接的过程。比如修改一个函数,Java 添加完成,可以直接启动测试,但是 C++ 可能会因为一行代码的修改,导致无数 cpp 文件的编译。
为什么 C/C++ 要分为头文件和源文件?
因为编译出来的二进制码(比如 .o、.obj、.lib、.dll)不包含自我描述的信息,要复用这种可行码的话得另外的文件。C# 和 Java 的可执行码自带元数据信息,但是这也意味着运行时的内存需求增加,毕竟自我描述的数据对最终用户来说是无用的。
cdecl、stdcall、fastcall、pascal
__cdecl 是 C Declaration 的缩写(declaration 声明),表示 C 语言默认的函数调用方法:所有参数从右到左依次入栈,这些参数由调用者清除,称为手动清栈。被调用函数不会要求调用者传递多少参数,调用者传递过多或者过少的参数,甚至完全不同的参数都不会产生编译阶段的错误。
__stdcall 调用规则使得被调用者来执行清栈操作(由被调用者函数自身将 ESP 拉高以维持堆栈平衡)
__fastcall 调用规则使得被调用者负责清理栈的操作(由被调用者函数自身将 ESP 拉高以维持堆栈平衡)
__pascal 则是从左到右依次入栈。并且,被调用者(函数自身)将自行完成清栈操作
| 调用规则 | 入栈顺序 | 清栈责任 |
|---|---|---|
| __cdecl | 从右到左 | 调用者 |
| __stdcall | 从右到左 | 被调用者 |
| __fastcall | 从右到左(先 EDX、ECX,再到堆栈) | 被调用者 |
| __pascal | 从左到右 | 被调用者 |
GatewayServer
也称之为连接服务器,网络游戏的客户端一般是连接到这里,然后再由该连接服务器根据不同的需要,把游戏消息转发给其它相应的服务器(逻辑和地图服务器)。也因为它是客户端直接连接的对象,它同时也承担了验证客户身份的工作。
Q&&A
1、Gateway 上的客户端连接类有多个连接的原因?
2、Scene 只有一个 SessionClient?
游戏网关服务器GatewayServer的作用:
- 游戏网关服务器可以作为客户端与 game server 的隔离作用
- 消息解析
- 与客户端保持连接,作为广播作用
- 消息合法性验证
- 转发消息到业务服务,针对不同的客户端消息分发到相应的服务处理
- 流量限制,消息分流作用
- 版本验证等
- 可扩展性、动态拓展
英语
1、技术 : Techniques
2、Idioms : 习语
3、Patterns : 模式
4、stumble[st^mbl] : 蹒跚、结巴、失足、绊脚、过失
5、aggregation[ˌæɡrɪˈɡeɪʃn] 聚集、集合、聚集体;集合体;聚合作用;凝聚;聚集作用;总量;
6、reconcile[ˈrekənsaɪl] 使和谐一致; 调和; 使配合; 使和解; 使和好如初; 将就; 妥协;
7、reduction[rɪˈdʌkʃn] 减少; 缩小; 降低; 减价; 折扣; (照片、地图、图片等的) 缩图,缩版;
8、preemptive[priˈɛmptɪv] 先发制人的; 先买的,有先买权的;
9、restore[rɪˈstɔː(r)] 恢复(某种情况或感受); 使复原; 使复位; 使复职; 修复; 整修;
10、immutable[ɪˈmjuːtəbl] 不可改变的; 永恒不变的;
11、stale[steɪl] adj. 不新鲜的; (空气) 污浊的; (烟味) 难闻的; 陈腐的; 没有新意的; 老掉牙的; n.(牛马、骆驼的)尿;
12、cancellation[ˌkænsəˈleɪʃn] 取消; 撤销; 被取消了的事物; 作废; 废除; 中止;
13、ephemeral[ɪˈfemərəl] 短暂的; 瞬息的;
Effective C++
条款25 C++ swap 函数
1、标准库 swap 函数
定义在 std 命名空间的函数模板:
1 | namespace std { |
标准库的 swap 实现调用了拷贝构造函数(对于非内置类型),并且有两次赋值运算,这在很多情况下是不满足我们的效率需求的(大型对象的拷贝是毫无必要的操作,我们仅需要交换指针,若存在容器类型,调用容器类的 swap 明显是更加正确的操作)。在 C++11 中,我们有如下的优化:
1 | template<typename T> |
移动方式的本质就是移交临时对象对资源的控制权,通常就是指针的替换,因此上述操作对存在移动构造和移动赋值运算的类来讲,已经可以基本满足要求,但是,对于未定义上述操作的类来讲,改进版本的 swap 操作并未有任何效率上的提升,因此,有必要定义类类型的 swap。
2、copy and swap 中的 swap 操作
1 | class A { |
上述操作并没有解决问题,我们希望能够像调用普通 swap 函数操作一样调用 swap(A& a, A& b),因此,我们下一步的操作就是在 std 命名空间内特化 swap 版本:
1 | namespace std { |
在 std 空间内的特化版本满足 C++ 标准的规定,这种扩充操作使得我们的特化版本对包含了 std 空间的文件都处于可见状态,因此,我们可以像以前一样使用 swap 进行交换:
1 | using std::swap; |
我们知道,C++ 允许对类模板全特化,但是对函数模板不允许全特化:
1 | template<typename T> |
同样的,std 内对 swap 的重载也不符合规定,我们的解决方案就是,在自定义的命名空间内定义 swap 函数:
1 | namespace Astuff { |
这样,我们在当前的命名空间内就拥有了 swap 的完整定义,那么为什么在使用时要加 using std::swap 呢?这句声明会使 std 命名空间的 swap 暴露出来,编译器会自动在当前命名空间和 std 空间内寻找最符合当前函数调用的 swap 版本,因此,以下的写法完全错误:
1 | A a, b; |
这种写法直接调用了 std 空间内的 swap 函数,因此并不符合大多数情况下的需求,using 版本才是最准确的版本:
1 | using std::swap; |
More Effective C++
条款25:将 constructor 和 non-member function 虚化
1、virtual constructor 是某种函数,视其获得的输入,可产生不同类型的对象。
2、copy-on-write 写入时才复制
3、子类写父类的函数时,虚函数的返回值可以与父类的不一样,子类返回一个引用或者指针。
结构体 Struct
1、C 中的 Struct 一个用途
一个复杂的 class object 的全部或部分到某个 C 函数去时,可以将数据封装起来。并保证拥有与 C 兼容的空间布局。
2、把单一元素的数组放在一个 struct 的尾端。每个 struct object 可以拥有可变大小的数组。(柔性数组)
字节对齐
要判断一个结构体所占的空间大小,大体来说分三步走:
- 先确定实际对齐单位,其由以下三个因素决定
(1) cpu 周期
win、vs、qt 默认8字节对齐,linux 32位,默认4字节对齐,linux 64位默认8字节对齐。
(2) 结构体最大成员(基本数据类型变量)
(3) 预编译指令 #pragma pack(n) 手动设置(n 只能填1 2 4 8 16)
上面三者取最小的。 - 除结构体的第一个成员外,其他所有的成员的地址相对于结构体地址(即它首个成员的地址)的偏移量必须为实际对齐单位或自身大小的整数倍(取两者中小的那个)
- 结构体的整体大小必须为实际对齐单位的整数倍
1 |
|
上面 nums 中,没有手动设置对齐单位,linux 64位系统的默认对齐单位是8字节,结构体 nums 的最大成员 double d 占8个字节,故实际对齐字节是二者最小,即8字节。
char a 放在结构体的起始地址;
short b 占2个字节,2小于实际对齐字节8,故 b 的起始地址相对于 a 的起始地址的偏移量必须为2的整数倍个字节;
int c 占4个字节,4小于实际对齐字节8,故 c 起始地址相对于 a 的起始地址的偏移量必须为4的整数倍个字节;
double d 占8个字节,8与实际对齐字节8相等,故 d 的起始地址相对于 a 的起始地址的偏移量须为8的整数倍个字节;
所以 nums 所占空间如下:1(a)+1(浪费的空间,由 b 的起始地址决定这1字节必须腾出)+2(b)+4(c)+8(d)=16个字节
1 | ubuntu@VM-0-9-ubuntu:~$ ./stru |
在结构体最后添加一个 char 数组
1 |
|
数组的类型是 char[13],并不是基本数据类型,这里仍然当做13个 char 型变量来处理,char 占1个字节,小于实际对齐字节8,所以这13个 char 型变量可以直接挨着 double d 后面放(最后结果看起来也就相当于整个数组挨着 double d 放置)。所以总的空间情况是:1(a)+1(浪费空间)+2(b)+4(c)+8(d)+13(arr)=29,但29并不满足上面三步走的最后一步:“整个结构体的大小必须是实际对齐单位的整数倍”,所以29+3(浪费空间)=32,所以最后nums 的空间情况是:1(a)+1(浪费空间)+2(b)+4(c)+8(d)+13(arr)+3(浪费空间)=32字节。
1 | ubuntu@VM-0-9-ubuntu:~$ ./stru |
结构体嵌套结构体的字节对齐和上面原理一样,唯一要注意的是子结构体的起始地址与母结构体的起地址之间的距离必须是子结构体最大成员或者实际对齐单位(还是取两者小的那个)的整数倍。
1 |
|
输出如下:
1 | ubuntu@VM-0-9-ubuntu:~$ ./stru |
对齐的作用和原因:各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如有些架构的 CPU 在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐。其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个 int 型(假设为 32 位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这 32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit数据。显然在读取效率上下降很多。
结构体内部存在 static 类型的变量
1 | struct S4 |
静态变量存放在全局数据区内,而 sizeof 计算栈中分配的空间的大小,故不计算在内,S4 的大小为 4+4=8。
(在自然对齐的结构体中,在 32 位系统内,对于某一个成员变量,如果前面的变量所占空间比自身小,那么前面的空间填充为满 4 字节,使得这个成员的地址从 4 字节整数倍开始,最后结构体的总体字节调整为 4 字节的整数倍即可)
1 | struct test |
sizeof(struct test) = 20。如果将最后两行注释去掉,仍然是 20 字节。规则是这样的,假设从 0x00000000 地址开始存储成员,那么 a 偏移为 1,但是 b 必须从 2 的地址开始,那么 a 就必须填充一个字节,那么 a、b 共占用 4 个字节,c 需要从 4 字节的整数倍开始,现在正好,上述不用填充,d 也从可以被 4 整除的字节数开始存储(现在正好,其实也是 8 字节的整数倍,这是凑巧了),连续填充 8 个字节,现在变成 0x0000010(16 进制),那么 e 的地址为 0x00000011,但是整个结构体的大小不是 4 字节的整数倍,最后需要填充 3 个字节,整体是 0x00000014,如果将最后两行注释去掉,那么仍然是 20 字节,需要填充的就是 g,填充 1 个字节。
范式
C++ 支持三种范式:
1、程序模型(procedural model)
2、抽象数据类型模型(abstract data type model ADT)
3、面向对象模型(object-oriented model)
inline
1、一个 inline 函数有静态链接、不会被文件以外者看到。
2、每一个 non-inline member function 只会诞生一个函数实例。
STL
STL find 函数用类指针的一个原因是可以应用到链表的 next
1、lower_bound 和 upper_bound 实现
lower_bound 算法返回第一个大于等于给定值所在的位置。设置两个指针 start 和 last,其中 start 指向数组的起始位置,last 指向数组末尾位置之后的位置。当 start 和 last 指向相同位置时循环结束。mid 指向 [start, last) 区间的中间位置,当中间位置元素值大于等于给定 val 时,说明第一个大于等于 val 值在 mid 位置的左边,更新 last 为 mid。当中间位置元素值小于给定的 val 时,说明第一个大于等于 val 值在 mid 右边,不包括 mid 所在的位置,更新 start 为 mid+1。
1、在从小到大的排序数组中
lower_bound(begin, end, num)
从数组的 begin 位置到 end-1 位置二分查找第一个大于或等于 num 的数字,找到返回该数字的地址,不存在则返回 end。通过返回的地址减去起始地址 begin,得到找到数字在数组中的下标。
upper_bound(begin, end, num)
从数组的 begin 位置到 end-1 位置二分查找第一个大于 num 的数字,找到返回该数字的地址,不存在则返回 end。通过返回的地址减去起始地址 begin,得到找到数字在数组中的下标。
2、在从大到小的排序数组中
重载 lower_bound() 和 upper_bound()
lower_bound(begin, end, num, greater
从数组的 begin 位置到 end-1 位置二分查找第一个小于或等于 num 的数字,找到返回该数字的地址,不存在则返回 end。通过返回的地址减去起始地址 begin,得到找到数字在数组中的下标。
upper_bound( begin,end,num,greater
从数组的 begin 位置到 end-1 位置二分查找第一个小于 num 的数字,找到返回该数字的地址,不存在则返回 end。通过返回的地址减去起始地址 begin,得到找到数字在数组中的下标。
1 | int lower_bound(vector<int>& nums, int target) |
upper_bound 算法返回第一个大于给定元素值所在的位置,设置两个指针 start 和 last,其中 start 指向数组的起始位置,last 指向数组末尾位置之后的位置,当 start 和 last 指向相同位置时循环结束,mid 指向 [start, last) 区间的中间位置,当中间位置元素值小于等于给定 val 时,说明第一个大于 val 值在 mid 位置的右边,更新 start 为 mid+1。当中间位置元素值大于给定元素时,说明第一大于在 mid 左边,包括 mid 所在位置,所以更新 last 为 mid。
1 | int upper_bound(vector<int>& nums, int target) |
lower_bound、upper_bound 例子
1 | 1 2 2 3 4 5 |
target = 2,则 lower_bound 返回的位置是 第 1 个位置,upper_bound 返回的位置是第 3 个位置。(从第 0 个位置开始)
upper_bound - lower_bound = 数组中 target 的个数。
1 |
|
SessionServer
Session 服务器上有所有的玩家(RelationUser)
游戏服务器中的数据库异步操作技术和游戏数据的保存机制
1、在游戏服务器中,处理玩家登陆需要向数据库查询玩家的账号和密码,玩家上线和下线需要对玩家的角色数据从数据库中读取和保存。
2、为了不阻塞逻辑线程,可以采用异步数据库访问的方式,即数据库操作请求提交给专门的数据库处理线程池,然后逻辑线程不再等待数据库处理结果,继续处理其他,不再阻塞在这里。
3、改成数据库异步处理后,为了保障数据安全,我们希望不只是玩家下线的时候才会保存玩家数据,同时也希望每隔一段时间统一保存所有在线玩家的数据,可以考虑这样的思路:假设我们有一个 GAMEDB 服务器,GAMEDB 缓存了所有在线玩家的角色数据,每次到保存时间,GAMEDB 就将所有在线玩家的数据(DBO)的副本都统一提交给 DB 线程池,让它保存数据,提交的过程很快,提交完后,GAMEDB 的逻辑线程仍能继续处理游戏服务器的更新和读取 CACHE 的请求。为什么要保存副本呢,DB 线程的执行保存队列的过程也许很耗时,但是队列中的数据都是 GAMEDB 提交 DBO 那个时刻的数据,这样就能保证玩家的游戏数据的完整性。
4、为提高性能,网络游戏服务器程序启动后一般都会把事先需要的数据从数据库提取到内存供使用,以减少读数据库的频率。
5、当然,网游开发中,遇到需要立即写库或者更新库的内容时,我们会立即向数据库服务器发送 insert、delete、update 等以期望数据库能立即更新我们的数据,比如玩家切换到新地图,这种数据就有必要立即提交到数据库:
- 写到数据服务(这个数据服务器就是程序中缓存,用来缓存一些所要提交的数据)中,并不直接写库,因为数据库不是你想象的那么高效;
- 业务服务实时写数据库,数据服务定时存盘,比如5分钟保存一次;
6、数据服务中心负责所有数据统一管理,提供实时的数据读写,多服务器环境下数据服务中心的处理能力直接关系到整个集群系统的性能,所有的关键数据库访问都它包装。一般对内存需求会很大,因为有大量数据要在内存缓存。
7、一般场景服务器 SceneServer 是没有数据库连接池的,存档的数据,都是通过档案服务器客户端 RecordClient 发送到 RecordServer(DBServer) 上的。
服务器传输层在异步模型下的基本使用序列
1、在主循环(TimeTick)中,不断尝试读取,看是否有什么数据可读
2、如果上一步返回有数据到达了,则读取数据
3、读取数据处理后,需要发送数据,则向网络写入数据(写的话,可以先发送到写的缓冲buffer、多缓存一些,然后::send() 出去)
网游比较特殊,最大的特点在于客户端和服务器端是要进行长连接的,客户端和服务器端基本上一直要保持连接,不是典型的 Request-Response 模式,Client 会主动给 Server 发送数据,Server 也可能主动往 Client 发送数据,生命周期比较长,一次发送的数据量比较小,但是数据交互发送比较频繁。由于要进行长连接,服务器端的 socket 就不能进行复用,单台服务器处理请求是有限的。
RAII
在编写 C++ 程序的时候,总是设法保证对象的构造和析构是成对出现的。
生命期和程序一样长的对象,直接使用全局对象(或 scope_ptr)或者做成 main() 的栈上对象。有如下发生串话场景:
从某个 TCP 连接 A 收到了一个 request,程序开始处理这个 request;处理可能要花一定的时间,为了避免耽误(阻塞)处理其他 request,程序记住了发来 request 的 TCP 连接,在某个线程池中处理这个请求;在处理完之后,会把 response 发回 TCP 连接 A。但是,在处理 request 的过程中,客户端断开了 TCP 连接 A,而另一个客户端刚好创建了新连接 B。程序不能只记住 TCP 连接 A 的文件描述符,而应该持有封装 socket 连接的 TcpConnection 对象,保证在处理 request 期间 TCP 连接 A 的文件描述符不会被关闭。或者持有 TcpConnection 对象的弱引用(week_ptr),这样能知道 socket 连接在处理 request 期间是否已经关闭了,fd=8 的文件描述符到底是“前世”还是“今生”。
在 C++ 项目中,自己写个 File Class,把项目用到的文件 IO 功能简单封装一下(以 RAII 手法封装 File* 或者 file descriptor 都可以),通常就能满足需要。记得把拷贝构造和赋值操作符禁用,在析构函数里释放资源,避免泄露内部的 handle。
如果要用 stream 方式做 logging,可以抛开繁重的 iostream,自己写一个简单的 LogStream,重载几个 operate<< 操作符,而且可以用 stack buffer,轻松做到线程安全与高效。
fork()
1 | int main() |
fork() 之后,子进程继承了父进程的几乎全部状态。子进程会继承地址空间和文件描述符,因此用于管理动态内存和文件描述符的 RAII class 都能正常工作。但子进程不会继承:
1、父进程的内存锁,mlock()、mlockall()
2、父进程的文件锁,fcntl()
3、父进程的某些定时器,settimer()、alarm()、timer_create()等等
fork() 一般不能在多线程程序中调用,因为 Linux 的 fork() 只克隆当前线程的 thread of control,不克隆其他线程。不能一下子 fork() 出一个和父进程一样的多线程子进程。Linux 没有 forkall() 这样的系统调用。因为其他线程可能等在 condition variable 上,可能阻塞在系统调用上,可能等着 mutex 以跨入临界区,还可能在密集的计算中,这些都不好全盘搬到子进程里。
其他线程可能正好位于临界区之内,持有了某个锁,而它突然死亡,再也没有机会去解锁了。如果子进程试图再对同一个 mutex 加锁,就会立刻死锁。在 fork() 之后,子进程就相当于处于 signal handler 之中,不能调用线程安全的函数(除非它是可重入的),而只能调用异步信号安全(async-signal-safe)函数。子进程不能调用:
1、malloc()。因为 malloc() 在访问全局状态时几乎肯定会加锁。
2、任何可能分配或释放内存的函数,包括 new、map::insert()、snprintf…..
3、任何 Pthreads 函数。不能用 pthread_cond_signal() 去通知父进程,只能通过读写 pipe() 来同步。
4、printf() 系列函数,因为其他线程可能恰好持有 stdout/stderr 的锁。
5、除了 man 7 signal 中明确列出的 “signal 安全” 函数之外的任何函数。
唯一安全的做法是在 fork() 之后立即调用 exec() 执行另一个程序,彻底隔断子进程与父进程的联系。
Signal信号
在多线程程序中,使用 signal 的第一原则是不要使用 signal
1、不要使用 signal 作为 IPC 的手段,包括不要使用 SIGUSR1 等信号来触发服务端的行为。可以采取增加监听端口的方式来实现双向的、可远程访问的进程控制。
2、不要使用基于 signal 实现的定时函数,包括 alarm/ualarm/settitimer/timer_create、sleep/usleep 等等。
3、不主动处理各种异常信号(SIGTERM、SIGINT 等等),只用默认语义:结束进程。有一个例外 SIGPIPE,服务器程序通常的做法是忽略此信号,否则如果对方断开连接,而本机继续 write 的话,会导致程序意外终止。
4、在没有别的替代方法的情况下(比如需要处理 SIGCHILD 信号),把异步信号转换为同步的文件描述符事件。传统的做法是在 signal handler 里往一个特定的 pipe() 写一个字节,在主程序中从这个 pipe 读取,从而纳入统一的 IO 事件处理框架中去。现代 Linux 的做法是采用 signalfd() 把信号直接转换为文件描述符事件,从根本上避免使用 signal handler。
文件描述符fd
O_NONBLOCK 的功能是开启非阻塞 IO,而文件描述符默认是阻塞的。
FD_CLOEXEC 的功能是让程序 exec() 时,进程会自动关闭这个文件描述符。而文件描述默认是被子进程继承的(这是传统 Unix 的一种典型 IPC,比如用 pipe() 在父子进程间单向通信)。
MySQL
MySQL 的客户端只支持同步操作,对于 UPDATE/INSERT/DELETE 之类只要行为不管结果的操作,可以用一个单独的线程来做,以降低服务线程的延迟。
Mysql 联合索引最左匹配原则
最左前缀匹配原则
在 mysql 建立联合索引时会遵循最左前缀匹配的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,示例:
对列 col1、列 col2 和列 col3 建一个联合索引
1 | KEY test_col1_col2_col3 on test(col1, col2, col3); |
联合索引 test_col1_col2_col3 实际建立了 (col1)、(col1, col2)、(col1, col2, col3) 三个索引。
1 | SELECT * FROM test WHERE col1=“1” AND clo2=“2” AND clo4=“4” |
上面这个查询语句执行时会依照最左前缀匹配原则,检索时会使用索引 (col1, col2) 进行数据匹配。
索引的字段可以是任意顺序的,如:
1 | SELECT * FROM test WHERE col1=“1” AND clo2=“2” |
这两个查询语句都会用到索引 (col1, col2),mysql 创建联合索引的规则是首先会对联合合索引的最左边的,也就是第一个字段 col1 的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个字段 col2 进行排序。其实就相当于实现了类似 order by col1 col2 这样一种排序规则。
有人会疑惑第二个查询语句不符合最左前缀匹配:首先可以肯定是两个查询语句都包含索引 (col1, col2) 中的 col1、col2 两个字段,只是顺序不一样,查询条件一样,最后所查询的结果肯定是一样的。既然结果是一样的,到底以何种顺序的查询方式最好呢?此时我们可以借助 mysql 查询优化器 explain,explain 会纠正 sql 语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。
为什么要使用联合索引
- 减少开销。建一个联合索引 (col1, col2, col3),实际相当于建了 (col1)、(col1, col2)、(col1, col2, col3) 三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
- 覆盖索引。对联合索引 (col1, col2, col3),如果有如下的
sql: select col1,col2,col3 from test where col1=1 and col2=2。那么 MySQL 可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机 io 操作。减少 io 操作,特别是随机 io,其实是 dba 主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。 - 效率高。索引列越多,通过索引筛选出的数据越少。有 1000W 条数据的表,有如下
sql:select from table where col1=1 and col2=2 and col3=3,假设每个条件可以筛选出 10% 的数据,如果只有单值索引,那么通过该索引能筛选出 1000W * 10% = 100w 条数据,然后再回表从 100W 条数据中找到符合 col2=2 and col3=3 的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出 1000W * 10% * 10% * 10% = 1W,效率提升可想而知!
引申
对于联合索引 (col1, col2, col3),查询语句 SELECT * FROM test WHERE col2=2;是否能够触发索引?
大多数人都会说 NO,实际上却是 YES。
1 | EXPLAIN SELECT * FROM test WHERE col2=2; |
观察上述两个 explain 结果中的 type 字段。查询中分别是:
- type: index
- type: ref
- index:这种类型表示 mysql 会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个联合索引的一部分,mysql 都可能会采用 index 类型的方式扫描。但是呢,缺点是效率不高,mysql 会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。所以,上述语句会触发索引。
- ref:这种类型表示 mysql 会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。
HTTP
一次 HTTP proxy 的请求如果没有命中本地 cache:
1、解析域名
2、建立连接
3、发送 HTTP 请求
4、等待对方回应
5、把结果返回给客户
这5步中和2个 sever 发生了3次 round-trip:
1、向 DNS 问域名,等待回复
2、向对方的 HTTP 服务器发起连接,等待 TCP 三路握手完成
3、向对方发送 HTTP request,等待对方 response
网络同步
网络同步 = 数据同步 + 表现同步,数据同步是后端操作,表现同步就是让前端对后端同步过来的数据进行进一步的处理从而达到表现上的一致。一般的 Web 服务器只是单纯的从服务器向客户端进行数据同步,不会把其他客户端的数据都发给你。游戏服务器对实时性要求比较高(尤其是 MMORPG、FPS 类型的网游)。综上 网络同步 = 实时的多端数据同步 + 实时的多端表现同步。网络同步是一个网络 IO 与 CPU 计算同样密集的游戏功能。
游戏服务器基础组件(Java)
1、网络组件
包括内网通信模块和外网通信模块、协议
2、数据库组件
玩家数据和全局数据的持久化
3、日志组件
异常日志(代码异常打印日志)、行为日志(为运营平台提供的行为日志)
4、配置组件
程序启动配置(如 ip、port、连接关系)和游戏相关配置(各种数据表格)
游戏逻辑模块(Java)
1、系统服务线程组
登录系统服务、好友系统服务、帮派系统服务…,可以将一个或者多服务挂载一个线程,也可以分别挂载不同线程
2、场景逻辑线程组
玩家的行走、战斗、道具获得、使用,系统服务线程组提供的系统服务基本都是通过 RPC 调用的方式为场景逻辑组线程提供服务。比如添加好友、场景逻辑线程上的玩家收到添加好友消息,然后通过 RPC 调用系统服务线程组的好友服务实现添加好友功能。
登录服务做了特殊处理,登录消息会直接分发到登录服务,登录服务进行验证,验证通过后会在场景服务线程组创建对应的角色通信对象与客户端进行通信。
进程和线程
资源
堆
是大家共有的空间,分全局堆和局部堆。全局堆就是所有没有分配的空间,局部堆就是用户分配的空间。堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是记得用完了要还给操作系统,要不然就是内存泄漏。栈
是线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈互相独立。因此,栈是 thread safe 的。操作系统在切换线程的时候会自动的切换栈,就是切换 ss/esp 寄存器。栈空间不需要在高级语言里面显式的分配和释放。
| 进程占有的资源 | 线程占有的资源 |
|---|---|
| 地址空间 | 栈 |
| 全局变量 | 寄存器 |
| 打开的文件 | 状态 |
| 子进程 | 程序计数器 |
| 信号量 | |
| 账户信息 |
程序计数器是用来存放下一条指令的地址的。当执行一条指令时,首先需要根据 PC 中存放的指令地址,将指令由内存取到指令寄存器中,此过程称为“取指令”。与此同时,PC 中的地址或自动加1或由转移指针给出下一条指今的地址。此后经过分析指令、执行指令、完成第一条指令的执行,而后根据 PC 取出第二条指令的地址,如此循环,执行每一条指令。
进程和线程区别
程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。正是这样的设计,大大提高了 CPU 的利用率。进程的出现让每个用户感觉到自己独享 CPU,因此,进程就是为了在 CPU 上实现多道编程而提出的。
进程的不足:
- 进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
- 进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
举个现实的例子:如果把我们上课的过程看成一个进程的话,那么我们要做的是耳朵听老师讲课,手上还要记笔记,脑子还要思考问题,这样才能高效的完成听课的任务。而如果只提供进程这个机制的话,上面这三件事将不能同时执行,同一时间只能做一件事,听的时候就不能记笔记,也不能用脑子思考,这是其一;如果老师在黑板上写演算过程,我们开始记笔记,而老师突然有一步推不下去了,阻塞住了,他在那边思考着,而我们呢,也不能干其他事,即使你想趁此时思考一下刚才没听懂的一个问题都不行,这是其二。
现在你应该明白了进程的缺陷了,而解决的办法很简单,我们完全可以让听、写、思三个独立的过程,并行起来,这样很明显可以提高听课的效率。而实际的操作系统中,也同样引入了这种类似的机制——线程。
进程属于在处理器这一层上提供的抽象;线程则属于在进程这个层次上再提供了一层并发的抽象。如果我们进入计算机体系结构里,就会发现,流水线提供的也是一种并发,不过是指令级的并发。这样,流水线、线程、进程就从低到高在三个层次上提供我们所迫切需要的并发。
区别:
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。
线程是进程的一个实体,是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器、一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
一个线程可以创建和撤销另一个线程,同一个进程中的多个线程之间可以并发执行。
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
用户级线程与核心级线程(线程的切换)
1、为什么要说线程的切换
操作系统是多进程的,我们关注的应该是进程之间的切换,那为什么关注线程的切换呢?因为理解了线程的切换之后可以更好的理解进程的切换,换句话说线程的切换是进程切换的基础。
每一个进程都包含一个映射表,如果进程切换了,那么程序选择的映射表肯定也不一样;进程的切换其实是包含两个部分的,第一个指令的切换,第二个映射表的切换。指令的切换就是从这段程序跳到另外一段程序执行,映射表切换就是执行不同的进程,所选择的映射表不一样。线程的切换只有指令的切换,同处于一个进程里面,不存在映射表的切换。进程的切换就是在线程切换的基础上加上映射表的切换。
2、线程的引入
多个进程可以“同时”执行,其实也就是换着执行,那么在同一个进程里面,不同的代码段能不能换着执行呢?比如在进程 A 里面有代码段 1、代码段 2、代码段 3;能不能先执行一下代码段 1,然后执行一下代码段 3,再执行一下代码段 2 呢?答案是可以的。进程的切换包括指令的切换和映射表的切换,那么同一个进程里面就没必要进行映射表的切换了,即只需要切换指令就可以了。上面所说的代码段其实就称为“线程”。
前面说了多线程只需要进行指令的切换就可以了;这样相对于进程来说,多线程保留了多进程的优点:并发。避免了进程切换的代价(切换映射表需要耗费比较多的时间)。如果能够将多线程的切换弄明白,那么多进程的切换其实也就直剩下了映射表的切换,这是典型的“分而治之”。
3、用户级线程
以前网速比较慢的时候,打开浏览器访问一个网页,首先弹出来的是网页的文字部分,然后是一些图片,最后才是一些小视频之类的。为什么呢?浏览器向服务器发起访问的程序是一个进程,它包含若干线程,比如:一个线程用来从服务器接收数据,一个线程用来显示文本,一个线程用来显示视频,一个线程用来显示图片等等。在网速比较慢的时候用来从服务器接收数据的线程要执行的时间比较长,因为一些图片和视频都比较大。如果要等这个线程运行完了之后再显示,那么电脑屏幕就会有一段时间什么东西都没有,这样用户体验就会比较差;一个比较合理的办法是:接受数据的线程接受完文本东西之后,就调用显示文本的线程将数据显示出来,然后再接受图片再显示,再接受视频再显示;这样至少可以保证电脑屏幕上始终有东西;相比前面的方法好很多,当然最根本的办法还是提高网速。
为什么浏览器向服务器请求数据的程序是一个进程,而不是多个?浏览器接受服务器的数据肯定都是存储在一个缓冲区里面的,并且这个缓冲区是共享的,如果是多个进程,那么肯定有多个映射表,也就是说如果程序里面存储数据的地址是连续的,经过不同的映射表之后,就会分布在内存的不同区域,这样肯定没有在一块地方好处理。
1、两个线程与一个栈
线程一
1 | 100 : A() |
线程二
1 | 300 : C() |
按照这个执行一下,首先从线程一的 A 函数开始,调用 B 函数,将 B 函数的返回地址 104 压栈,然后进入 B 函数;在 B 函数内部使用Yield1 切换到线程二的 C() 函数里面去,同时将 Yield1 的返回地址压栈,此时栈中的数据如下:
1 | 104 204 |
Yield1 的伪代码应该是:
1 | void Yield1() |
现在执行到了线程二,计划是在 D 函数里面通过 Yield2 跳到线程一的 204 这个地址,完成线程的切换。调用 C 函数,同时将 304 这个地址压栈,跳到 D 函数里面执行,在 D 函数里面调用 Yield2,同时将 404 压栈。Yield2 的伪代码应该是:
1 | void Yield2() |
目前栈里面的数据应该是:
1 | 104 204 304 404 |
跳到 204 之后,接着执行 B 函数剩下的内容,执行完内容之后,执行函数 B 的 “}” 相当于 ret,弹栈,此时栈顶的地址是 404,B 函数应该是返回到 104 处,而不是 404 处;这里就出现了问题。怎么处理?
2、从一个栈到两个栈
处理方法是使用两个栈,在不同的线程里面使用不同的栈。在线程一中使用栈一,线程二中使用栈二。
重新执行一下上面那个程序,从 A 函数开始执行,在 B 函数里面调用 Yield1 进入线程二的 C 函数之后,线程一对应的栈一中的内容应该是:
1 | 104 204 |
执行到 D 函数的 Yield2 之后,线程二对应的栈二的内容应该是:
1 | 304 404 |
在 Yield2 里面做的第一件事就应该是切换栈,如何切换?肯定需要一个数据结构将原来栈一的地址保存起来,这个数据结构就是 TCB(Thread control block);当前栈的栈顶地址是存放在 cpu 里面的 esp 寄存器里面的,因此只需要改变 esp 的值就可以切换栈了。
1 | void Yield2() |
jmp 到 204 之后,执行完 B 函数剩下的代码之后执行 B 函数的 “}”,即弹栈,这时栈顶是 204,也就是又跳到 204 去了,显然有问题,但是比前面已经好很多了,因为不会跳到另外一个线程里去。那现在为什么会这样呢?原因是 Yield2() 直接跳到 204 之后,而没有将栈中的 204 弹出去,如果 Yield2 跳到 204 这个位置,同时将栈中的 204 弹出去就好了。其实这个可以实现,修改 Yield2 如下:
1 | void Yield2() |
没错,就是将 jmp 204 去掉就可以了,利用 Yield2 的 “}” 弹栈同时跳到 204 地址处,执行完 B 函数之后,通过 B 函数的 “}” 再次弹栈到 104 处。
4、核心级线程
1、多处理器和多核的区别
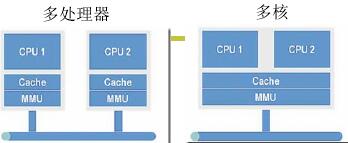
多处理器每一个 CPU 都有一套自己的 MMU。多核是所有的 CPU 共用一套 MMU,也就是多个 CPU 的内存映射关系是一致的。
多核就有种单个进程的概念,在这个进程内部所有的线程都是共用一套 MMU 的。多处理器就有种多进程的概念,每个 CPU 的 MMU 都不一样。因此对于同一个进程来说,多核可以同时执行这个进程里面的线程,但是多处理器不行,只有多线程才能将多核利用起来,因为现在电脑都是多核的,所以这是多线程的一大用处。这里的线程指的是核心级线程。核心级线程可以将每一个线程对应到具体的 CPU 上。
2、核心级线程与用户级线程有什么区别呢?
核心级线程需要在用户态和核心态里面跑,在用户态里跑需要一个用户栈,在核心态里面跑需要一个核心栈。用户栈和核心栈合起来称为一套栈,这就是核心级线程与用户级线程一个很重要的区别,从一个栈变成了一套栈。用户级线程用 TCB 切换栈的时候是在一个栈与另外一个栈之间切换,核心级线程就是在一套栈与另外一套栈之间的切换(核心级线程切换),核心级线程的 TCB 应该是在内核态里面。
3、用户栈与内核栈之间的关联
内核栈什么时候出现?当线程进入内核的时候就应该建立一个属于这个线程的内核栈,那么线程是如何进入系统内核的?通过 INT 中断。当线程下一次进入内核的时候,操作系统可以根据一些硬件寄存器来知道这是哪个线程,它对应的内核栈在哪里。同时会将用户态的栈的位置(SS、SP)和程序执行到哪个地方了(CS、IP)都压入内核栈。等线程在内核里面执行完(也就是 IRET 指令)之后就根据进入时存入的 SS、SP 的值找到用户态中对应栈的位置,根据存入的 CS、IP 的值找到程序执行到哪个地方。
1 | 100:A() |
上面的 “- - - - -” 表示用户态和核心态的分界;首先该线程调用 B 函数,将 104 压栈(用户栈),进入 B 函数之后调用 read() 这个系统调用,同时将 204 压栈(用户栈),进入 read() 系统调用通过 int0x80 这个中断号进入内核态,执行到
1 | sys_read() |
switch_to() 方法就是切换线程,形参 cur 表示当前线程的 TCB,next 表示下一个执行线程的 TCB。这个函数首先将目前 esp 寄存器的值存入 cur.TCB.esp,将 next.TCB.esp 放入 esp 寄存器里面;其实就是从当前线程的内核栈切换到 next 线程的内核栈。这里要明白一件事,内核级线程自己的代码还是在用户态的,只是进入内核态完成系统调用,也就是逛一圈之后还是要回去执行的。因此切换到 next 线程就是要根据 next 线程的内核栈找到这个线程阻塞前执行到的位置,并接着执行。所以切换到 next 线程的内核栈之后应该通过一条包含 IRET 指令的语句进入到用户态执行这个线程的代码。这样就从 cur 线程切换到 next 线程。
Redis
如果 CPU 成为 Redis 瓶颈,或者不想让服务器其他 CUP 核闲置,可以考虑多起几个 Redis 进程,Redis 是 key-value 数据库,不是关系数据库,数据之间没有约束。只要客户端分清哪些 key 放在哪个 Redis 进程上就可以了。
分布式事务
假如数据库在提交事务的时候突然断电,那么它是怎么样恢复的呢?因为分布式的网络环境很复杂,这种“断电”故障要比单机多很多,所以我们在做分布式系统的时候,最先考虑的就是这种情况。这些异常可能有机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的 TCP、存储数据丢失、其他异常等等。
const
const 只修饰离它最近的类型符号
1、const 修饰的一级指针
1 |
|
上述代码证明出 const int * p 中 const 修饰的是 int,则 const int * p 指的是:*p 所代表的整形值是常量,不能被直接修改,而指针 p 本身是变量,可以被修改。(不能通过修改 p 指针指向地址 a 的数据来修改 *p 的值,但可以通过修改 p 指针本身所储存的地址来修改 p 的值。)
另外 const int * p 和 int const * p 是一样的,因为与int const * p 中与 const 相邻的类型只有 int,const 修饰的还是 int。
1 |
|
从上述代码可以看出,int * const p 中 const 修饰的是 int *,int * const p 指的是:指针 p 本身是常量,不能被修改。而 *p 所代表的是整形变量,可以被直接修改。(指针 p 本身存储的地址不能被修改,而指针 p 指向地址 a 的值可以被修改。)
2、const 修饰的二级指针
- const int ** p
const int ** p 表示 ** p 代表的整形内存放的是常量,不能够被修改。而指针 p 本身是变量,可以被修改。(const 修饰的是 int) - int ** const p
int ** const p 表示指针 p 本身是常量,不能被修改。而 ** p 代表的整形内存放的值是变量,可以被修改。(const 修饰 的是int **) - int * const * p
int * const * p 是一个二级指针,const 修饰的是 int * ,代表指针 * p 的值是常量,不能被修改。而 ** p 所代表的整形内存放的是变量,可以被修改。指针 p 本身是变量,也可以被修改。(通俗来说,就是二级指针 p 所指向的一级指针 * p 不能被修改,而 ** p 所代表的整形,可以被修改。指针 p 本身,也可以被修改。)
重载
为什么函数重载不可以根据返回类型区分?
1 | float max(int a, int b); |
当调用 max(1, 2) 时,无法确定调用的是哪个,单从这一点上来说,仅返回值类型不同的重载是不应该允许的。
函数的返回值只是作为函数运行之后的一个状态,它是保持方法的调用者与被调用者进行通信的关键。并不能作为某个方法的标识。
sizeof
sizeof 实际上是获取了数据在内存中所占用的存储空间,以字节为单位来计数。
C 语言会自动在在双引号 “” 括起来的内容的末尾补上 “\0” 代表结束,ASCII 中的0号位也占用一个字符。
1 |
|
C/C++ 中,sizeof() 只是运算符号,是编译的时候确定大小的。动态分配是运行过程中得到大小的,也就是说 C++ 中 new 出来的内存,sizeof 都无法统计的,退一步说,即使是 new 出来的空间也有可能失败,所以 sizeof 无法统计动态分配的内存大小。
1 | //使用new关键字,在堆区开辟一个int数组 |
sizeof() 为物理存储大小,strlen() 为除去 \0 后逻辑字符串长度。
Socket
socket 选项
1、SO_REUSEADDR
一般来说,一个端口释放后会等待两分钟之后才能再被使用,SO_REUSEADDR 是让端口释放后立即就可以被再次使用。
SO_REUSEADDR 用于对 TCP 套接字处于 TIME_WAIT 状态下的 socket,才可以重复绑定使用。
server 程序总是应该在调用 bind() 之前设置 SO_REUSEADDR 套接字选项 TCP,先调用 close() 的一方会进入 TIME_WAIT 状态。
SO_REUSEADDR 提供如下四个功能:
- 允许启动一个监听服务器并捆绑其众所周知端口,即使以前建立的将此端口用做他们的本地端口的连接仍存在。这通常是重启监听服务器时出现,若不设置此选项,则 bind 时将出错。
- 允许在同一端口上启动同一服务器的多个实例,只要每个实例捆绑一个不同的本地 IP 地址即可。对于 TCP,我们根本不可能启动捆绑相同 IP 地址和相同端口号的多个服务器。
- 允许单个进程捆绑同一端口到多个套接口上,只要每个捆绑指定不同的本地 IP 地址即可,这一般不用于 TCP 服务器。
SO_REUSEADDR 允许完全重复的捆绑:
- 当一个 IP 地址和端口绑定到某个套接口上时,还允许此 IP 地址和端口捆绑到另一个套接口上。一般来说,这个特性仅在支持多播的系统上才有,而且只对 UDP 套接口而言(TCP 不支持多播)。
SO_REUSEPORT 选项有如下语义:
此选项允许完全重复捆绑,但仅在想捆绑相同 IP 地址和端口的套接口都指定了此套接口选项才行。
如果被捆绑的 IP 地址是一个多播地址,则 SO_REUSEADDR 和 SO_REUSEPORT 等效。
使用这两个套接口选项的建议:
- 在所有 TCP 服务器中,在调用 bind 之前设置 SO_REUSEADDR 套接口选项;
- 当编写一个同一时刻在同一主机上可运行多次的多播应用程序时,设置 SO_REUSEADDR 选项,并将本组的多播地址作为本地 IP 地址捆绑。
2、SO_REUSEPORT
目前常见的网络编程模型就是多进程或多线程,根据accpet的位置,分为如下场景2种场景
- 单进程或线程创建 socket,并进行 listen 和 accept,接收到连接后创建进程和线程处理连接
- 单进程或线程创建 socket,并进行 listen,预先创建好多个工作进程或线程 accept() 在同一个服务器套接字
这两种模型解充分发挥了多核 CPU 的优势,虽然可以做到线程和 CPU 核绑定,但都会存在:
- 单一 listener 工作进程或线程在高速的连接接入处理时会成为瓶颈
- 多个线程之间竞争获取服务套接字
- 缓存行跳跃
- 很难做到 CPU 之间的负载均衡
- 随着核数的扩展,性能并没有随着提升
SO_REUSEPORT 支持多个进程或者线程绑定到同一端口,提高服务器程序的性能,解决的问题:
- 允许多个套接字 bind()/listen() 同一个 TCP/UDP 端口
- 每一个线程拥有自己的服务器套接字
- 在服务器套接字上没有了锁的竞争
- 内核层面实现负载均衡
- 安全层面,监听同一个端口的套接字只能位于同一个用户下面
其核心的实现主要有三点:
- 扩展 socket option,增加 SO_REUSEPORT 选项,用来设置 reuseport
- 修改 bind 系统调用实现,以便支持可以绑定到相同的 IP 和端口
- 修改处理新建连接的实现,查找 listener 的时候,能够支持在监听相同 IP 和端口的多个 sock 之间均衡选择
- 有了 SO_RESUEPORT 后,每个进程可以自己创建 socket、bind、listen、accept 相同的地址和端口,各自是独立平等的
- 让多进程监听同一个端口,各个进程中 accept socket fd 不一样,有新连接建立时,内核只会唤醒一个进程来 accept,并且保证唤醒的均衡性
Accept 发生在三次握手的哪个阶段?
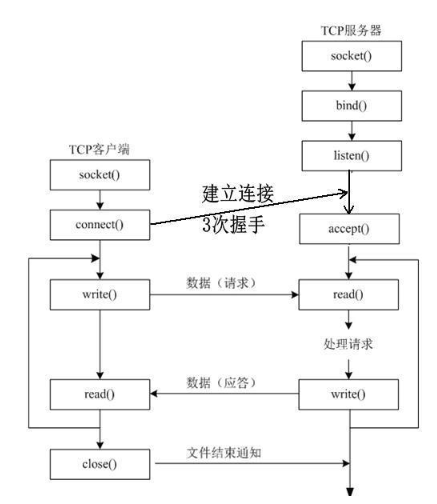
accept 过程发生在三次握手之后,三次握手完成后,客户端和服务器就建立了 tcp 连接并可以进行数据交互了。这时可以调用 accept 函数获得此连接。
客户端调用 connect 的时候,就是发一个 syn,服务端 accept 的时候,实际上是从内核的 accept 队列里面取一个连接,如果这个队列为空,则进程阻塞(阻塞模式下)。如果 accept 返回则说明成功取到一个连接,返回到应用层。大致的过程是客户端发一个 syn 之后,服务端将这个连接放入到 backlog 队列,在收到客户端的 ack 之后将这个请求移到 accept 队列。所以 accept 一定是发生在三次握手之后,connect只是发一个 syn 而已。
socket 分为两种,一种套接字正如 accept 的参数 sockfd,它是 listen socket,在调用 listen 函数之后,一个 socket 会从主动连接的套接字变为 listen 套接字;而 accept 返回是一个连接套接字,它代表着一个网络已经存在的点对点连接。以后的数据交互就是基于这个连接socket,而之前的那个 listen socket 可以继续工作,从而接收更多的连接。
connect() 在第二次握手返回。
惊群
惊群效应就是当一个 fd 的事件被触发时,所有等待这个 fd 的线程或进程都被唤醒。一般都是 socket 的 accept() 会导致惊群(当然也可以弄成一堆线程/进程阻塞 read 一个 fd),很多个进程都 block 在 server socket 的 accept(),一但有客户端进来,所有进程的 accept() 都会返回,但是只有一个进程会读到数据,就是惊群。实际上现在的 Linux 内核实现中不会出现惊群了,只会有一个进程被唤醒(Linux2.6内核)。使用 mutex 锁住多个线程是不会惊群的,在某个线程解锁后,只会有一个线程会获得锁,其它的继续等待。
指针
为什么 C++ 调用空指针对象的成员函数可以运行通过?
1 |
|
这个问题可以阐明“静态绑定”和“动态绑定”的区别。
真正的原因是:因为对于非虚成员函数,C++ 这门语言是静态绑定的。这也是 C++ 语言和其它语言 Java, Python 的一个显著区别。以此下面的语句为例:
1 | somenull->foo(); |
这语句的意图是:调用对象 somenull 的 foo 成员函数。如果这句话在 Java 或 Python 等动态绑定的语言之中,编译器生成的代码大概是:找到 somenull 的 foo 成员函数,调用它。(注意,这里的找到是程序运行的时候才找的,这也是所谓动态绑定的含义:运行时才绑定这个函数名与其对应的实际代码。有些地方也称这种机制为迟绑定,晚绑定。)
但是对于 C++。为了保证程序的运行时效率,C++ 的设计者认为凡是编译时能确定的事情,就不要拖到运行时再查找了。所以 C++ 的编译器看到这句话会这么做:
1:查找 somenull 的类型,发现它有一个非虚的成员函数叫 foo。(编译器处理)
2:找到了,在这里生成一个函数调用,直接调 B::foo(somenull)。所以到了运行时,由于 foo() 函数里面并没有任何需要解引用 somenull 指针的代码,所以真实情况下也不会引发 segment fault。这里对成员函数的解析,和查找其对应的代码的工作都是在编译阶段完成而非运行时完成的,这就是所谓的静态绑定,也叫早绑定。正确理解 C++ 的静态绑定可以理解一些特殊情况下 C++ 的行为。
mutable
C++ 中的 mutable 有两种作用。
1、类中的 mutable
可变的只能用来形容变量,而不可能是函数或者类本身。然而,既然是变量,那么它本来就是可变的,也没必要使用 mutable 来修饰。那么,mutable 就只能用来形容某种不变的东西了。
C++ 中,不可变的变量,称之为常量,使用 const 修饰。
事实上,mutable 是用来修饰一个 const 示例的部分可变的数据成员的。如果说得更清晰一点,就是说 mutable 的出现,将 C++ 中的 const 的概念分成了两种。
- 二进制层面的 const,也就是绝对的常量,在任何情况下都不可修改(除非用 const_cast)。
- 引入 mutable 之后,C++ 可以有逻辑层面的 const,也就是对一个常量实例来说,从外部观察,它是常量不可修改,但是内部可以有非常量的状态。
显而易见,mutable 只能用来修饰类的数据成员,而被 mutable 修饰的数据成员,可以在 const 成员函数中修改。
1 | class HashTable |
对哈希表的查询操作,在逻辑上不应该修改哈希表本身。因此,HashTable::lookup 是一个 const 成员函数。在 HashTable::lookup 中,我们使用了 last_key_ 和 last_value_ 实现了一个简单的缓存逻辑。当传入的 key 与前次查询的 last_key_ 一致时,直接返回 last_value_; 否则,则返回实际查询得到的 value 并更新 last_key_ 和 last_value_。
在这里,last_key_ 和 last_value_ 是 HashTable 的数据成员。按照一般的理解,const 成员函数是不允许修改数据成员的。但是,另一方面,last_key_ 和 last_value_ 在类的外部是看不到的,从逻辑上说,修改它们的值,外部是没有感知的,因此也就不会破坏逻辑上的 const。为了解决这一矛盾,我们用 mutable 来修饰 last_key_ 和 last_value_,以便在 lookup 函数中更新缓存的键值。
2、Lambda 表达式中的 mutable
C++11 引入了 Lambda 表达式,程序员可以凭此创建匿名函数。在 Lambda 表达式的设计中,捕获变量有几种方式;其中按值捕获(Caputre by Value)的方式不允许程序员在 Lambda 函数的函数体中修改捕获的变量。而以 mutable 修饰 Lambda 函数,则可以打破这种限制。
1 | int x{0}; |
需要注意的是,上述 f1 的函数体中,虽然我们给 x 做了赋值操作,但是这一操作仅只在函数内部生效。即,实际是给拷贝至函数内部的 x 进行赋值,而外部的 x 的值依旧是 0。
函数
为什么要在 C++ 函数中最后添加默认参数?
在参数列表中的任何位置都可能具有默认参数,但这会增加函数调用的复杂性和歧义性(对于编译器,可能更重要的是对于函数用户)。
如果要在各个参数位置使用默认参数,则几乎可以肯定地做到这一点,方法是编写重载,然后简单地转过来并调用内联完全参数化的函数:
1 | int foo(int x, int y); |
相当于:
1 | int foo(int x = 0, int y); |
通常,函数参数由编译器处理,并以从右到左的顺序放置在堆栈中。因此,应该首先评估具有默认值的任何参数。(这适用于 __cdecl,它通常是 VC++ 和 __stdcall 函数声明的默认值。)
C++11
1、default_random_engine
以前获取伪随机数都是用的 rand,想要获取两个数之间的伪随机数,方法如下:
1 | int min,max; |
《C++ Primer 5th Edition》里面介绍了使用 default_random_engine 来获取随机数,并且指出“C++ 程序不应该使用库函数 rand,而应使用 default_random_engine 类来恰当的分布类对象。”用这种新方法获取两个数之间的伪随机数的方法如下:
1 | int min,max; |
有一个问题,就是多次调用同一对范围和引擎时,每次生成的数都是一样的。为了避免这个情况,需要在定义范围和引擎时,将其定义为 static的:
1 | static default_random_engine e; |
关于设置种子,既可以在定义时设置种子,也可以创建完成后再设置种子,方法如下:
1 | default_random_engine e1(32767); |
如果要设置时间为种子,方法如下:
1 | default_random_engine e(time(0)); |
time 返回时间的单位是秒,所以如果是自动过程的一部分反复运行,比如用在循环中,那么因为间隔时间不够,所以设置的种子其实是一样的。
enable_shared_from_this
enable_shared_from_this 是一个模板类,定义于头文件 < memory >
1 | template<class T> |
std::enable_shared_from_this 能让一个对象(假设其名为 t ,且已被一个 std::shared_ptr 对象 pt 管理)安全地生成其他额外的 std::shared_ptr 实例(假设名为 pt1, pt2, … ),它们与 pt 共享对象 t 的所有权。
若一个类 T 继承 std::enable_shared_from_this
1、使用场合
当类 A 被 share_ptr 管理,且在类 A 的成员函数里需要把当前类对象作为参数传给其他函数时,就需要传递一个指向自身的 share_ptr。
为何不直接传递this指针
使用智能指针的初衷就是为了方便资源管理,如果在某些地方使用智能指针,某些地方使用原始指针,很容易破坏智能指针的语义,从而产生各种错误。可以直接传递 share_ptr
么?
答案是不能,因为这样会造成2个非共享的 share_ptr 指向同一个对象,未增加引用计数导对象被析构两次。
1 |
|
正确的实现如下:
1 |
|
2、为何会出现这种使用场合
因为在异步调用中,存在一个保活机制,异步函数执行的时间点我们是无法确定的,然而异步函数可能会使用到异步调用之前就存在的变量。为了保证该变量在异步函数执期间一直有效,我们可以传递一个指向自身的 share_ptr 给异步函数,这样在异步函数执行期间 share_ptr 所管理的对象就不会析构,所使用的变量也会一直有效了(保活)。
类 Class
实现一个不能被继承的类
1、方法一
最直观的解决方法就是将其构造函数声明为私有的,这样就可以阻止子类构造对象了。但是这样的话,就无法构造本身的对象了,就无法利用了。
既然这样,我们又可以想定义一个静态方法来构造类和释放类。
1 |
|
但是这样只能在堆上创建,无法再栈上实现创建类。这就是私有的构造函数的局限性。
2、方法二
利用友元不能被继承的特性,可以实现这样的类。
设计一个模板辅助类 Base,将构造函数声明为私有的;再设计一个不能继承的类 FinalClass,将 FinalClass 作为 Base 的友元类。FinalClass 虚继承 Base。
1 |
|
类 Base 的构造函数和析构函数因为是私有的,只有 Base 类的友元可以访问,FinalClass 类在继承时将模板的参数设置为了 FinalClass 类,所以构造 FinalClass 类对象时们可以直接访问父类(Base)的构造函数。
为什么必须是虚继承呢?
虚继承的功能是:当出现了菱形继承体系的时候,使用虚继承可以防止二义性,即子孙类不会继承多个原始祖先类。
那么虚继承如何解决这种二义性的呢?从具有虚基类的类继承的类在初始化时进行了特殊处理,在虚派生中,由最低层次的派生类的构造函数初始化虚基类。
结合上面的代码来解释:C 在调用构造函数时,不会先调用 FinalClass 的构造函数,而是直接调用 Base 的构造函数,C 不是 Base 的友元类,所以无法访问。这样的话 C 就不能继承 FinalClass。
注 C++11 的已经加入了 final 关键字,直接在类后面加上 final 关键字,就可以防止该类被继承。
操作系统
死锁
是指两个或两个以上的进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
死锁发生的条件
互斥条件:线程对资源的访问是排他性的,如果一个线程占用了某资源,那么其他线程必须处于等待状态,直到资源被释放。
请求和保持条件:线程 T1 至少已经保持了对一个资源 R1 的占用,但又提出对另一个资源 R2 的请求,而此时,资源 R2 被其他线程 T2 占用,于是该线程 T1 也必须等待,但又对自己保持的资源 R1 不释放。
不剥夺条件:线程已获得的资源,在未使用完之前,不能被其他线程剥夺,只能在使用完以后由自己释放。
环路等待条件:在死锁发生时,必然存在一个“进程-资源环形链”,即 {p0,p1,p2,…pn},进程 p0(或线程)等待 p1 占用的资源,p1 等待 p2 占用的资源,pn 等待 p0 占用的资源。(最直观的理解是,p0 等待 p1 占用的资源,而 p1 在等待 p0 占用的资源,于是两个进程就相互等待)。
活锁
是指线程 1 可以使用资源,但它很礼貌,让其他线程先使用资源,线程 2 也可以使用资源,但它很绅士,也让其他线程先使用资源。这样你让我,我让你,最后两个线程都无法使用资源。
1 | /************************ |
饥饿
是指如果线程 T1 占用了资源 R,线程 T2 又请求封锁 R,于是 T2 等待。T3 也请求资源 R,当 T1 释放了 R上 的封锁后,系统首先批准了T3 的请求,T2 仍然等待。然后 T4 又请求封锁 R,当 T3 释放了 R 上的封锁之后,系统又批准了 T4 的请求…,T2 可能永远等待。
String
C 语言实现 itoa 函数
1 | /* A C++ program to implement itoa() */ |
参考原文
1、C++内存对象布局
2、C++对象模型
3、网络同步在游戏历史中的发展变化(一)—— 网络同步与网络架构
4、C++11新特性之十:enable_shared_from_this
- 本文标题:C++游戏服务器知识点散记
- 本文作者:beyondhxl
- 本文链接:https://www.beyondhxl.com/post/70ae5d6.html
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!






