
select、poll和epoll的原理和区别浅析
select、poll 和 epoll 都是操作系统中 IO 多路复用实现的方法。
零、IO 多路复用
设计这样一个应用程序,该程序从标准输入接收数据输入,然后通过套接字发送出去,同时,该程序也通过套接字接收对方发送的数据流。
我们可以使用 fgets 方法等待标准输入,但是一旦这样做,就没有办法在套接字有数据的时候读出数据;我们也可以使用 read 方法等待套接字有数据返回,但是这样做,也没有办法在标准输入有数据的情况下,读入数据并发送给对方。
I/O 多路复用的设计初衷就是解决这样的场景。我们可以把标准输入、套接字等都看做 I/O 的一路,多路复用的意思,就是在任何一路 I/O 有“事件”发生的情况下,通知应用程序去处理相应的 I/O 事件,这样我们的程序就变成了“多面手”,在同一时刻仿佛可以处理多个 I/O 事件。
一、select
select 函数就是这样一种常见的 I/O 多路复用技术。使用 select 函数,通知内核挂起进程,当一个或多个 I/O 事件发生后,控制权返还给应用程序,由应用程序进行 I/O 事件的处理。
这些 I/O 事件的类型非常多,比如:
- 标准输入文件描述符准备好可以读。
- 监听套接字准备好,新的连接已经建立成功。
- 已连接套接字准备好可以写。
- 如果一个 I/O 事件等待超过了 10 秒,发生了超时事件。
1.1、select 原理
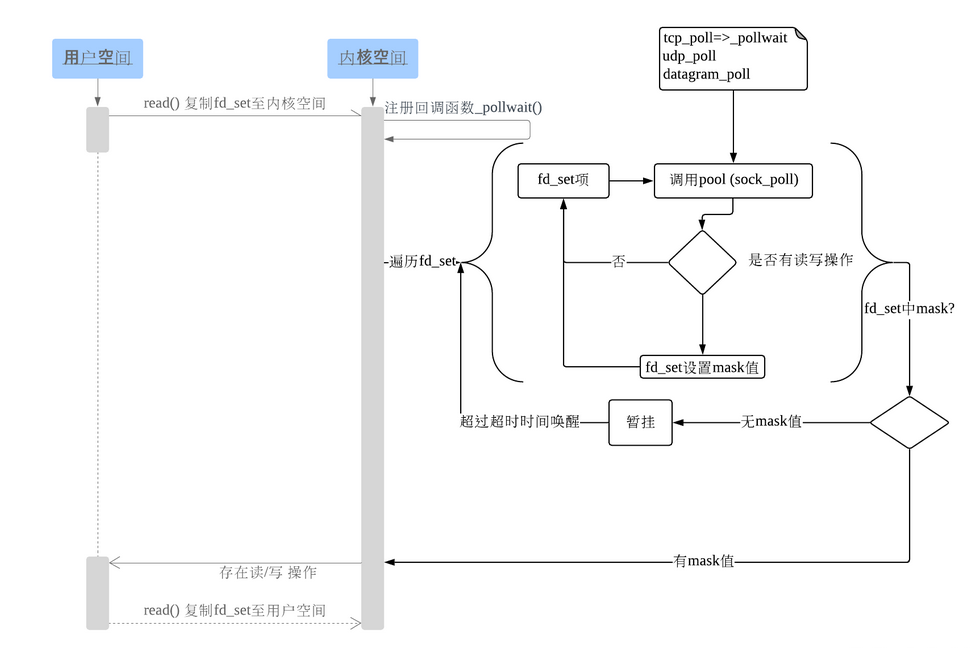
使用 select 可以实现同时处理多个网络连接的 IO 请求,基本原理就是程序调用 select,然后整个程序就进入阻塞状态,这个时候,kernel 内核就会轮询检查所有 select 负责的文件描述符 fd,当找到其中哪个文件描述符数据准备好了,会返回给 select,select 通知系统调用,将数据从内核复制到进程的缓存区。
1.2、select 函数的使用方法
1 | int select(int maxfd, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout); |
在这个函数中,maxfd 表示的是待测试的描述符基数,它的值是待测试的最大描述符加 1。比如现在的 select 待测试的描述符集合是{0,1,4},那么 maxfd 就是 5。
紧接着的是三个描述符集合,分别是读描述符集合 readset、写描述符集合 writeset 和异常描述符集合 exceptset,这三个分别通知内核,在哪些描述符上检测数据可以读,可以写和有异常发生。
以下的宏设置这些描述符集合:
1 | void FD_ZERO(fd_set *fdset); |
可以这样想象,下面一个向量代表了一个描述符集合,其中,这个向量的每个元素都是二进制数中的 0 或者 1。
1 | a[maxfd-1], ..., a[1], a[0] |
我们按照这样的思路来理解这些宏:
- FD_ZERO 用来将这个向量的所有元素都设置成 0;
- FD_SET 用来把对应套接字 fd 的元素 a[fd] 设置成 1;
- FD_CLR 用来把对应套接字 fd 的元素 a[fd] 设置成 0;
- FD_ISSET 对这个向量进行检测,判断出对应套接字的元素 a[fd] 是 0 还是 1。
其中 0 代表不需要处理,1 代表需要处理。
这个时候再来理解为什么描述字集合{0,1,4},对应的 maxfd 是 5,而不是 4,就比较方便了。
因为这个向量对应的是下面这样的:
1 | a[4],a[3],a[2],a[1],a[0] |
待测试的描述符个数显然是 5, 而不是 4。
三个描述符集合中的每一个都可以设置成空,这样就表示不需要内核进行相关的检测。
最后一个参数是 timeval 结构体时间:
1 | struct timeval { |
这个参数设置成不同的值,会有不同的可能:
第一个可能是设置成空 (NULL),表示如果没有 I/O 事件发生,则 select 一直等待下去。
第二个可能是设置一个非零的值,这个表示等待固定的一段时间后从 select 阻塞调用中返回。
第三个可能是将 tv_sec 和 tv_usec 都设置成 0,表示根本不等待,检测完毕立即返回,这种情况使用得比较少。
1.3、程序例子
1 | int main(int argc, char **argv) { |
程序的 12 行通过 FD_ZERO 初始化了一个描述符集合,这个描述符读集合是空的:
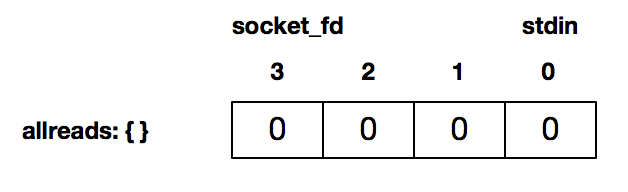
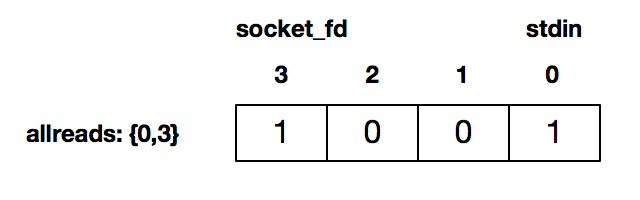
接下来程序的第 13 和 14 行,分别使用 FD_SET 将描述符 0 (即标准输入),以及连接套接字描述符 3 设置为待检测:
接下来的 16-51 行是循环检测,这里我们没有阻塞在 fgets 或 read 调用,而是通过 select 来检测套接字描述字有数据可读,或者标准输入有数据可读。比如,当用户通过标准输入使得标准输入描述符可读时,返回的 readmask 的值为:
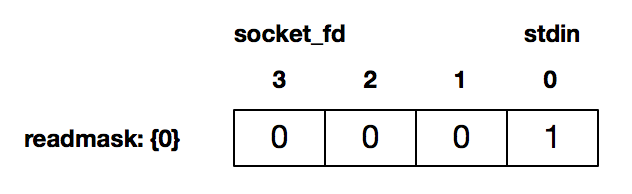
这个时候 select 调用返回,可以使用 FD_ISSET 来判断哪个描述符准备好可读了。如上图所示,这个时候是标准输入可读,37-51 行程序读入后发送给对端。
如果是连接描述字准备好可读了,第 24 行判断为真,使用 read 将套接字数据读出。
我们需要注意的是,这个程序的 17-18 行非常重要,初学者很容易在这里掉坑里去。
第 17 行是每次测试完之后,重新设置待测试的描述符集合。你可以看到上面的例子,在 select 测试之前的数据是{0,3},select 测试之后就变成了{0}。
这是因为 select 调用每次完成测试之后,内核都会修改描述符集合,通过修改完的描述符集合来和应用程序交互,应用程序使用 FD_ISSET 来对每个描述符进行判断,从而知道什么样的事件发生。
第 18 行则是使用 socket_fd+1 来表示待测试的描述符基数。切记需要 +1。
1.4、套接字描述符就绪条件
当我们说 select 测试返回,某个套接字准备好可读,表示什么样的事件发生呢?
第一种情况是套接字接收缓冲区有数据可以读,如果我们使用 read 函数去执行读操作,肯定不会被阻塞,而是会直接读到这部分数据。
第二种情况是对方发送了 FIN,使用 read 函数执行读操作,不会被阻塞,直接返回 0。
第三种情况是针对一个监听套接字而言的,有已经完成的连接建立,此时使用 accept 函数去执行不会阻塞,直接返回已经完成的连接。
第四种情况是套接字有错误待处理,使用 read 函数去执行读操作,不阻塞,且返回 -1。
总结成一句话就是,内核通知我们套接字有数据可以读了,使用 read 函数不会阻塞。
刚开始理解某个套接字可写的时候,会有一个错觉,总是从应用程序角度出发去理解套接字可写,开始是这样想的,当应用程序完成相应的计算,有数据准备发送给对端了,可以往套接字写,对应的就是套接字可写。
其实这个理解是非常不正确的,select 检测套接字可写,完全是基于套接字本身的特性来说的,具体来说有以下几种情况。
第一种是套接字发送缓冲区足够大,如果我们使用套接字进行 write 操作,将不会被阻塞,直接返回。
第二种是连接的写半边已经关闭,如果继续进行写操作将会产生 SIGPIPE 信号。
第三种是套接字上有错误待处理,使用 write 函数去执行写操作,不阻塞,且返回 -1。
总结成一句话就是,内核通知我们套接字可以往里写了,使用 write 函数就不会阻塞。
1.5、总结
select 函数提供了最基本的 I/O 多路复用方法,在使用 select 时,我们需要建立两个重要的认识:
- 描述符基数是当前最大描述符 +1;
- 每次 select 调用完成之后,记得要重置待测试集合。
1.6、思考题
1、第一道,select 可以对诸如 UNIX 管道 (pipe) 这样的描述字进行检测么?如果可以,检测的就绪条件是什么呢?
可以,就绪条件是有数据可读(检测可读事件)。是否可以监测可写事件需要实验。
2、第二道,根据我们前面的描述,一个描述符集合哪些描述符被设置为 1,需要进行检测是完全可以知道的,你认为 select 函数里一定需要传入描述字基数这个值么?请你分析一下这样设计的目的又是什么呢?
不一定需要传入,那样的话内核中 for 循环需要遍历整个集合,效率低。传入基数可以减小遍历范围,提高效率。
二、poll
poll 是除了 select 之外,另一种普遍使用的 I/O 多路复用技术,和 select 相比,它和内核交互的数据结构有所变化,另外,也突破了文件描述符的个数限制。
1 | int poll(struct pollfd *fds, unsigned long nfds, int timeout); |
这个函数里面输入了三个参数,第一个参数是一个 pollfd 的数组。其中 pollfd 的结构如下:
1 | struct pollfd { |
这个结构体由三个部分组成,首先是描述符 fd,然后是描述符上待检测的事件类型 events,注意这里的 events 可以表示多个不同的事件,具体的实现可以通过使用二进制掩码位操作来完成,例如,POLLIN 和 POLLOUT 可以表示读和写事件。
1 |
和 select 非常不同的地方在于,poll 每次检测之后的结果不会修改原来的传入值,而是将结果保留在 revents 字段中,这样就不需要每次检测完都得重置待检测的描述字和感兴趣的事件。我们可以把 revents 理解成“returned events”。
events 类型的事件可以分为两大类。
第一类是可读事件,有以下几种:
1 |
一般我们在程序里面有 POLLIN 即可。套接字可读事件和 select 的 readset 基本一致,是系统内核通知应用程序有数据可以读,通过 read 函数执行操作不会被阻塞。
第二类是可写事件,有以下几种:
1 |
一般我们在程序里面统一使用 POLLOUT。套接字可写事件和 select 的 writeset 基本一致,是系统内核通知套接字缓冲区已准备好,通过 write 函数执行写操作不会被阻塞。
以上两大类的事件都可以在“returned events”得到复用。还有另一大类事件,没有办法通过 poll 向系统内核递交检测请求,只能通过“returned events”来加以检测,这类事件是各种错误事件。
1 |
参数 nfds 描述的是数组 fds 的大小,简单说,就是向 poll 申请的事件检测的个数。
最后一个参数 timeout,描述了 poll 的行为。
如果是一个 <0 的数,表示在有事件发生之前永远等待;如果是 0,表示不阻塞进程,立即返回;如果是一个 >0 的数,表示 poll 调用方等待指定的毫秒数后返回。
关于返回值,当有错误发生时,poll 函数的返回值为 -1;如果在指定的时间到达之前没有任何事件发生,则返回 0,否则就返回检测到的事件个数,也就是“returned events”中非 0 的描述符个数。
poll 函数有一点非常好,如果我们不想对某个 pollfd 结构进行事件检测,可以把它对应的 pollfd 结构的 fd 成员设置成一个负值。这样,poll 函数将忽略这样的 events 事件,检测完成以后,所对应的“returned events”的成员值也将设置为 0。
和 select 函数对比一下,我们发现 poll 函数和 select 不一样的地方就是,在 select 里面,文件描述符的个数已经随着 fd_set 的实现而固定,没有办法对此进行配置;而在 poll 函数里,我们可以控制 pollfd 结构的数组大小,这意味着我们可以突破原来 select 函数最大描述符的限制,在这种情况下,应用程序调用者需要分配 pollfd 数组并通知 poll 函数该数组的大小。
2.1、基于 poll 的服务器程序
这个程序可以同时处理多个客户端连接,并且一旦有客户端数据接收后,同步地回显回去。这已经是一个颇具高并发处理的服务器原型了,再加上后面讲到的非阻塞 I/O 和多线程等技术,基本上就是可使用的准生产级别了。
1 |
|
一开始需要创建一个监听套接字,并绑定在本地的地址和端口上,这在第 10 行调用 tcp_server_listen 函数来完成。
在第 13 行,我初始化了一个 pollfd 数组,并命名为 event_set,之所以叫这个名字,是引用 pollfd 数组确实代表了检测的事件集合。这里数组的大小固定为 INIT_SIZE,这在实际的生产环境肯定是需要改进的。
监听套接字上如果有连接建立完成,也是可以通过 I/O 事件复用来检测到的。在第 14-15 行,将监听套接字 listen_fd 和对应的 POLLRDNORM 事件加入到 event_set 里,表示我们期望系统内核检测监听套接字上的连接建立完成事件。
如果对应 pollfd 里的文件描述字 fd 为负数,poll 函数将会忽略这个 pollfd,所以我们在第 18-21 行将 event_set 数组里其他没有用到的 fd 统统设置为 -1。这里 -1 也表示了当前 pollfd 没有被使用的意思。
下面我们的程序进入一个无限循环,在这个循环体内,第 24 行调用 poll 函数来进行事件检测。poll 函数传入的参数为 event_set 数组,数组大小 INIT_SIZE 和 -1。这里之所以传入 INIT_SIZE,是因为 poll 函数已经能保证可以自动忽略 fd 为 -1 的 pollfd,否则我们每次都需要计算一下 event_size 里真正需要被检测的元素大小;timeout 设置为 -1,表示在 I/O 事件发生之前 poll 调用一直阻塞。
如果系统内核检测到监听套接字上的连接建立事件,就进入到第 28 行的判断分支。我们看到,使用了如 event_set[0].revent 来和对应的事件类型进行位与操作,这个技巧大家一定要记住,这是因为 event 都是通过二进制位来进行记录的,位与操作是和对应的二进制位进行操作,一个文件描述字是可以对应到多个事件类型的。
在这个分支里,调用 accept 函数获取了连接描述字。接下来,33-38 行做了一件事,就是把连接描述字 connect_fd 也加入到 event_set 里,而且说明了我们感兴趣的事件类型为 POLLRDNORM,也就是套接字上有数据可以读。在这里,我们从数组里查找一个没有没占用的位置,也就是 fd 为 -1 的位置,然后把 fd 设置为新的连接套接字 connect_fd。
如果在数组里找不到这样一个位置,说明我们的 event_set 已经被很多连接充满了,没有办法接收更多的连接了,这就是第 41-42 行所做的事情。
第 45-46 行是一个加速优化能力,因为 poll 返回的一个整数,说明了这次 I/O 事件描述符的个数,如果处理完监听套接字之后,就已经完成了这次 I/O 复用所要处理的事情,那么我们就可以跳过后面的处理,再次进入 poll 调用。
接下来的循环处理是查看 event_set 里面其他的事件,也就是已连接套接字的可读事件。这是通过遍历 event_set 数组来完成的。
如果数组里的 pollfd 的 fd 为 -1,说明这个 pollfd 没有递交有效的检测,直接跳过;来到第 53 行,通过检测 revents 的事件类型是 POLLRDNORM 或者 POLLERR,我们可以进行读操作。在第 54 行,读取数据正常之后,再通过 write 操作回显给客户端;在第 58 行,如果读到 EOF 或者是连接重置,则关闭这个连接,并且把 event_set 对应的 pollfd 重置;第 61 行读取数据失败。
和前面的优化加速处理一样,第 65-66 行是判断如果事件已经被完全处理完之后,直接跳过对 event_set 的循环处理,再次来到 poll 调用。
2.2、总结
poll 是另一种在各种 UNIX 系统上被广泛支持的 I/O 多路复用技术,虽然名声没有 select 那么响,能力一点不比 select 差,而且因为可以突破 select 文件描述符的个数限制,在高并发的场景下尤其占优势。这一讲我们编写了一个基于 poll 的服务器程序,希望你从中学会 poll 的用法。
2.3、思考题
第一道,在我们的程序里 event_set 数组的大小固定为 INIT_SIZE,这在实际的生产环境肯定是需要改进的。你知道如何改进吗?
1、采用动态分配数组的方式
2、可以把所有的描述符 push_back 到一个 vector 等类似的容器当中,直接对容器取 size 就可以获得数量
第二道,如果我们进行了改进,那么接下来把连接描述字 connect_fd 也加入到 event_set 里,如何配合进行改造呢?
把新连接上来的 connfd 添加进去,对上面问题的容器进行一次取 size 操作就行了
三、epoll
具体可以参考epoll实现原理分析这篇文章。
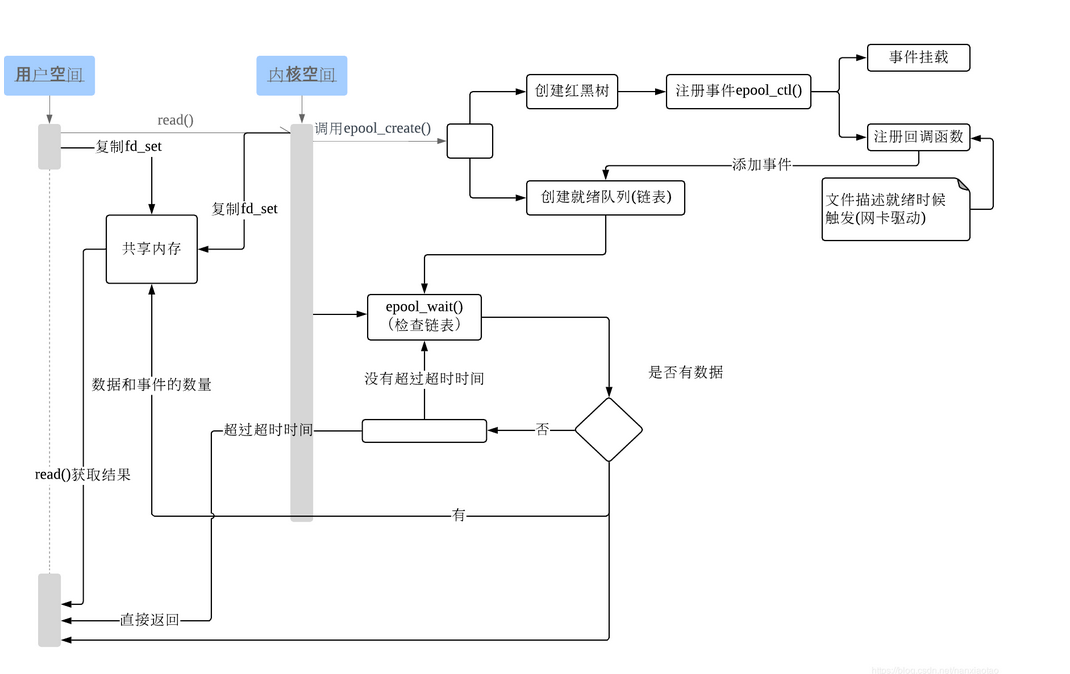
四、总结
I/O 多路复用和阻塞 I/O 其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个 system call (select 和 recvfrom),而blocking IO 只调用了一个 system call (recvfrom)。但是,用 select 的优势在于它可以同时处理多个 connection。
所以,如果处理的连接数不是很高的话,使用 select/epoll 的 web server 不一定比使用 multi-threading + blocking IO 的 web server 性能更好,可能延迟还更大。select/epoll 的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
4.1、select 缺点
进程可以打开的 fd 数量有限制,32 位机 1024 个,64 位 2048 个,原因是存储 fd 的是一个固定大小的数组。
select 方法本质其实就是维护了一个文件描述符(fd)数组,以此为基础,实现 IO 多路复用的功能。这个 fd 数组有长度限制,在 32 位系统中,最大值为 1024 个,而在 64 位系统中,最大值为 2048 个。
select 方法被调用,首先需要将 fd_set 从用户空间拷贝到内核空间,然后内核用 poll 机制(此 poll 机制非 IO 多路复用的那个 poll 方法)直到有一个 fd 活跃,或者超时了,方法返回。
对 socket 进行扫描是线性扫描,即采用轮询的方法,效率较低。
用户空间和内核空间之间复制数据非常的消耗资源。
select 方法返回后,需要轮询 fd_set,以检查出发生 IO 事件的 fd。这样一套下来,select 方法的缺点就很明显了:
- fd_set 在用户空间和内核空间的频繁复制,效率低
- 单个进程可监控的 fd 数量有限制,无论是 1024 还是 2048,对于很多情景来说都是不够用的
- 基于轮询来实现,效率低
4.2、poll
poll 的基本原理和 select 非常的类似,但是采用的是链表来存储 fd,且 poll 相比 select 不会修改描述符。poll 相对于 select 提供了更多的事件类型,并且对描述符的重复利用比 select 高。
select 和 poll 的返回结果没有声明哪些描述符已经准备好了,如果返回值大于0,应用进程就需要使用轮询的方式找到 IO 完成的描述符。这也是影响效率的一大因素。
4.3 epoll
epoll 主要解决了这些问题:
- 对 fd 的数量没有限制,所以最大数量与能打开的 fd 数量有关
- epoll 不再需要每次调用都从用户空间将 fd_set 复制到内核
- select 和 poll 都是主动去轮询,需要遍历每个 fd。而 epoll 采用的是被动触发的方式,给 fd 注册了相应的事件的时候,为每个 fd 指定了一个回调函数,当数据准备好后,就会把就绪的 fd 加入到就绪队列中,epoll_wait 的工作方式实际上就是在这个就绪队列中查看有没有就绪的 fd,如果有,就唤醒就绪队列上的等待者,然后调用回调函数。
- 就是 select 和 poll 只能通知有 fd 已经就绪了,但不能知道究竟是哪个 fd 就绪,所以 select 和 poll 就要去主动轮询一遍找到就绪的 fd。而 epoll 则是不但可以知道有 fd 可以就绪,而且还具体可以知道就绪 fd 的编号,所以直接找到就可以,不用轮询。这也是主动式和被动式的区别。
epoll 有两种触发方式:LT(水平触发)、ET(边缘触发)
- LT 模式:当 epoll_wait() 检查到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll_wait() 会再次通知进程。是默认的一种模式,并且同时支持 Blocking 和 No-Blocking。
- ET 模式:和 LT 模式不同的是,通知之后进程必须立即处理事件,下次再调用 epoll_wait() 时不会再得到事件到达的通知。ET 模式很大程度上减少了 epoll 事件被重复触发的次数,因此效率比 LT 模式要高。只支持 No-Blocking,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
ET 模式下每次 write 或 read 需要循环 write 或 read 直到返回 EAGAIN 错误。以读操作为例,这是因为 ET 模式只在 socket 描述符状态发生变化时才触发事件,如果不一次把 socket 内核缓冲区的数据读完,会导致 socket 内核缓冲区中即使还有一部分数据,该 socket 的可读事件也不会被触发。根据上面的讨论,若 ET 模式下使用阻塞 IO,则程序一定会阻塞在最后一次 write 或 read 操作,因此说 ET 模式下一定要使用非阻塞 IO。
ET 模式在很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。epoll 工作在 ET 模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
4.4 应用场景
1、select 应用场景
select 的 timeout 参数精度为 1nm,比 poll 和 epoll 的 1ms 精度更高,因此 select 适合实时性要求比较高的场景。select 的可移植性非常的好。
2、poll 应用场景
poll 没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用 poll 而不是 select。
3、epoll 应用场景
只能运行在 linux 平台下,有大量的描述符需要同时轮询,并且这些连接最好是长连接。在监听少量的描述符的场合,体现不出 epoll 的优势。
在需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成了每次需要对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁的系统调用降低了效率。并且因为 epoll 的描述符存储在内核中,不容易调试。
原文链接:
1、大名⿍⿍的select:看我如何同时感知多个I/O事件
2、poll:另一种I/O多路复用
3、浅谈select,poll和epoll的区别
- 本文标题:select、poll和epoll的原理和区别浅析
- 本文作者:beyondhxl
- 本文链接:https://www.beyondhxl.com/post/2fc34bd1.html
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!






