
epoll实现原理分析(转载)
epoll 是 Linux 平台下的一种特有的多路复用 IO 实现方式,与传统的 select、poll 相比,epoll 在性能上有很大的提升。
epoll 可以说是和 poll 非常相似的一种 I/O 多路复用技术,有些朋友将 epoll 归为异步 I/O,我觉得这是不正确的。本质上 epoll 还是一种 I/O 多路复用技术, epoll 通过监控注册的多个描述字,来进行 I/O 事件的分发处理。不同于 poll 的是,epoll 不仅提供了默认的 level-triggered(水平触发)机制,还提供了性能更为强劲的 edge-triggered(边缘触发)机制。
一、epoll 的用法
使用 epoll 进行网络程序的编写,需要三个步骤,分别是 epoll_create,epoll_ctl 和 epoll_wait。
epoll_create
1 | int epoll_create(int size); |
epoll_create() 方法创建了一个 epoll 实例,参数 size 是由于历史原因遗留下来的,现在不起作用。从 Linux 2.6.8 开始,参数 size 被自动忽略,但是该值仍需要一个大于 0 的整数。这个 epoll 实例被用来调用 epoll_ctl 和 epoll_wait,如果这个 epoll 实例不再需要,比如服务器正常关机,需要调用 close() 方法释放 epoll 实例,这样系统内核可以回收 epoll 实例所分配使用的内核资源。
epoll_create1() 的用法和 epoll_create() 基本一致,如果 epoll_create1() 的输入 flags 为 0,则和 epoll_create() 一样,内核自动忽略。可以增加如 EPOLL_CLOEXEC 的额外选项。
epoll_ctl
1 | int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); |
在创建完 epoll 实例之后,可以通过调用 epoll_ctl 往这个 epoll 实例增加或删除对应文件描述符监控的事件。函数 epll_ctl 有 4 个入口参数。
第一个参数 epfd 是刚刚调用 epoll_create 创建的 epoll 实例描述字,可以简单理解成是 epoll 句柄。
第二个参数表示增加,删除还是修改一个监控事件,它有三个选项可供选择:
- EPOLL_CTL_ADD:向 epoll 实例注册文件描述符对应的事件;
- EPOLL_CTL_DEL:向 epoll 实例删除文件描述符对应的事件;
- EPOLL_CTL_MOD:修改文件描述符对应的事件。
第三个参数是注册的事件的文件描述符,比如一个监听套接字。
第四个参数表示的是注册的事件类型,并且可以在这个结构体里设置用户需要的数据,其中最为常见的是使用联合结构里的 fd 字段,表示事件所对应的文件描述符。
1 | typedef union epoll_data { |
这里 epoll 仍旧使用了基于 mask 的事件类型,我们重点看一下这几种事件类型:
- EPOLLIN:表示对应的文件描述字可以读;
- EPOLLOUT:表示对应的文件描述字可以写;
- EPOLLRDHUP:表示套接字的一端已经关闭,或者半关闭;
- EPOLLHUP:表示对应的文件描述字被挂起;
- EPOLLET:设置为 edge-triggered(边缘触发),默认为 level-triggered(水平触发)。
epoll_wait
1 | int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); |
epoll_wait() 函数类似之前的 poll 和 select 函数,调用者进程被挂起,在等待内核 I/O 事件的分发。
这个函数的第一个参数是 epoll 实例描述字,也就是 epoll 句柄。
第二个参数返回给用户空间需要处理的 I/O 事件,这是一个数组,数组的大小由 epoll_wait 的返回值决定,这个数组的每个元素都是一个需要待处理的 I/O 事件,其中 epoll_event.events 表示具体的事件类型,事件类型取值和 epoll_ctl 可设置的值一样,这个 epoll_event 结构体里的 data 值就是在 epoll_ctl 那里设置的 data,也就是用户空间和内核空间调用时需要的数据。
第三个参数是一个大于 0 的整数,表示 epoll_wait 可以返回的最大事件值。
第四个参数是 epoll_wait 阻塞调用的超时值,如果这个值设置为 -1,表示不超时;如果设置为 0 则立即返回,即使没有任何 I/O 事件发生。
二、epoll 实例
实例代码解析
1 |
|
程序的第 116 行调用 epoll_create1(0) 创建了一个 epoll 实例。
第 121-125 行,调用 epoll_ctl 将监听套接字对应的 I/O 事件进行了注册,这样在有新的连接建立之后,就可以感知到。注意这里使用的是 edge-triggered(边缘触发)。
第 128 行为返回的 event 数组使用 calloc 分配了内存。
主循环调用 epoll_wait 函数分发 I/O 事件,当 epoll_wait 成功返回时,通过遍历返回的 event 数组,就直接可以知道发生的 I/O 事件。
第 134-139 行判断了返回的事件各种错误情况。
第 140-154 行是监听套接字上有事件发生的情况下,调用 accept 获取已建立连接,并将该连接设置为非阻塞,再调用 epoll_ctl 把已连接套接字对应的可读事件注册到 epoll 实例中。这里我们使用了 event_data 里面的 fd 字段,将连接套接字存储其中。
第 156-177 行,处理了已连接套接字上的可读事件,读取字节流,编码后再回应给客户端。
实验
启动 epoll 服务器
1 | ./epoll01 |
再启动几个 telnet 客户端,可以看到有连接建立情况下,epoll_wait 迅速从挂起状态结束;并且套接字上有数据可读时,epoll_wait 也迅速结束挂起状态,这时候通过 read 可以读取套接字接收缓冲区上的数据。
1 | telnet 127.0.0.1 43211 |
edge-triggered VS level-triggered
对于 edge-triggered 和 level-triggered,一个是边缘触发,一个是水平触发。也有文章从电子脉冲角度来解读的,总体上,给初学者的带来的感受是理解上有困难。
这里有两个程序,我们用这个程序来说明一下这两者之间的不同。
在这两个程序里,即使已连接套接字上有数据可读,我们也不调用 read 函数去读,只是简单地打印出一句话。
第一个程序我们设置为 edge-triggered,即边缘触发。开启这个服务器程序,用 telnet 连接上,输入一些字符,我们看到,服务器端只从 epoll_wait 中苏醒过一次,就是第一次有数据可读的时候。
1 | ./epoll02 |
1 | telnet 127.0.0.1 43211 |
第二个程序我们设置为 level-triggered,即水平触发。然后按照同样的步骤来一次,观察服务器端,这一次我们可以看到,服务器端不断地从 epoll_wait 中苏醒,告诉我们有数据需要读取。
1 | ./epoll03 |
这就是两者的区别,水平触发的意思是只要满足事件的条件,比如有数据需要读,就一直不断地把这个事件传递给用户;而边缘触发的意思是只有第一次满足条件的时候才触发,之后就不会再传递同样的事件了。
一般我们认为,边缘触发的效率比条件触发的效率要高,这一点也是 epoll 的杀手锏之一。
三、底层实现分析
基本的数据结构
在开始研究源代码之前,我们先看一下 epoll 中使用的数据结构,分别是 eventpoll、epitem 和 eppoll_entry。
我们先看一下 eventpoll 这个数据结构,这个数据结构是我们在调用 epoll_create 之后内核侧创建的一个句柄,表示了一个 epoll 实例。后续如果我们再调用 epoll_ctl 和 epoll_wait 等,都是对这个 eventpoll 数据进行操作,这部分数据会被保存在 epoll_create 创建的匿名文件 file 的 private_data 字段中。
1 | /* |
下图展示了 eventpoll 对象与被监听的文件关系: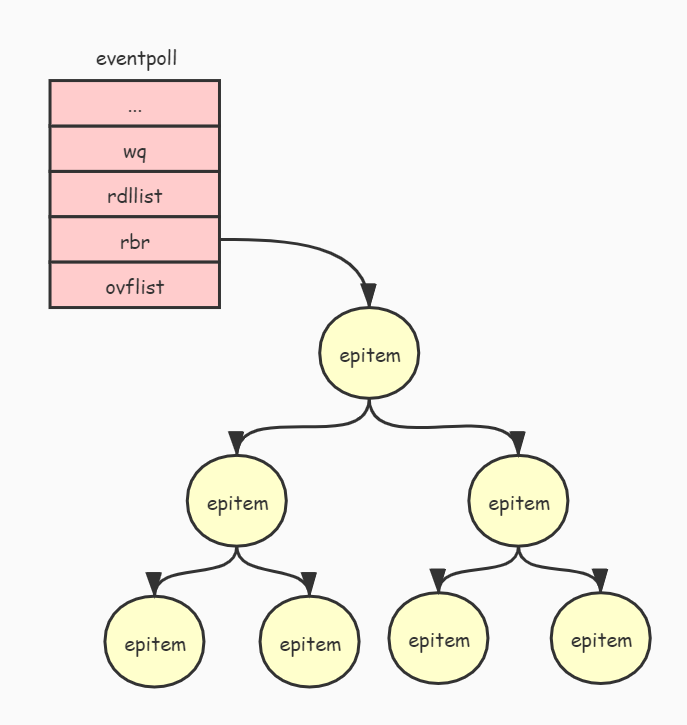
每当我们调用 epoll_ctl 增加一个 fd 时,内核就会为我们创建出一个 epitem 实例,并且把这个实例作为红黑树的一个子节点,增加到 eventpoll 结构体中的红黑树中,对应的字段是 rbr。这之后,查找每一个 fd 上是否有事件发生都是通过红黑树上的 epitem 来操作。
1 |
|
每次当一个 fd 关联到一个 epoll 实例,就会有一个 eppoll_entry 产生。eppoll_entry 的结构如下:
1 |
|
epoll_create
我们在使用 epoll 的时候,首先会调用 epoll_create 来创建一个 epoll 实例。这个函数是如何工作的呢?
首先,epoll_create 会对传入的 flags 参数做简单的验证。
1 | /* Check the EPOLL_* constant for consistency. */ |
接下来,内核申请分配 eventpoll 需要的内存空间。
1 | /* Create the internal data structure ("struct eventpoll"). |
在接下来,epoll_create 为 epoll 实例分配了匿名文件和文件描述字,其中 fd 是文件描述字,file 是一个匿名文件。这里充分体现了 UNIX 下一切都是文件的思想。注意,eventpoll 的实例会保存一份匿名文件的引用,通过调用 fd_install 函数将匿名文件和文件描述字完成了绑定。
最后,这个文件描述字作为 epoll 的文件句柄,被返回给 epoll_create 的调用者。
1 | /* |
epoll_ctl
查找 epoll 实例
首先,epoll_ctl 函数通过 epoll 实例句柄来获得对应的匿名文件,这一点很好理解,UNIX 下一切都是文件,epoll 的实例也是一个匿名文件。
1 | //获得epoll实例对应的匿名文件 |
接下来,获得添加的套接字对应的文件,这里 tf 表示的是 target file,即待处理的目标文件。
1 | /* Get the "struct file *" for the target file */ |
再接下来,进行了一系列的数据验证,以保证用户传入的参数是合法的,比如 epfd 真的是一个 epoll 实例句柄,而不是一个普通文件描述符。
1 | /* The target file descriptor must support poll */ |
如果获得了一个真正的 epoll 实例句柄,就可以通过 private_data 获取之前创建的 eventpoll 实例了。
1 | /* |
红黑树查找
接下来 epoll_ctl 通过目标文件和对应描述字,在红黑树中查找是否存在该套接字,这也是 epoll 为什么高效的地方。红黑树(RB-tree)是一种常见的数据结构,这里 eventpoll 通过红黑树跟踪了当前监听的所有文件描述字,而这棵树的根就保存在 eventpoll 数据结构中。
1 | /* RB tree root used to store monitored fd structs */ |
对于每个被监听的文件描述字,都有一个对应的 epitem 与之对应,epitem 作为红黑树中的节点就保存在红黑树中。
1 | /* |
红黑树是一棵二叉树,作为二叉树上的节点,epitem 必须提供比较能力,以便可以按大小顺序构建出一棵有序的二叉树。其排序能力是依靠 epoll_filefd 结构体来完成的,epoll_filefd 可以简单理解为需要监听的文件描述字,它对应到二叉树上的节点。
可以看到这个还是比较好理解的,按照文件的地址大小排序。如果两个相同,就按照文件描述字来排序。
1 | struct epoll_filefd { |
在进行完红黑树查找之后,如果发现是一个 ADD 操作,并且在树中没有找到对应的二叉树节点,就会调用 ep_insert 进行二叉树节点的增加。
1 | case EPOLL_CTL_ADD: |
ep_insert
ep_insert 首先判断当前监控的文件值是否超过了 /proc/sys/fs/epoll/max_user_watches 的预设最大值,如果超过了则直接返回错误。
1 | user_watches = atomic_long_read(&ep->user->epoll_watches); |
接下来是分配资源和初始化动作。
1 | /* 从著名的 slab 中分配一个 epitem */ |
再接下来的事情非常重要,ep_insert 会为加入的每个文件描述字设置回调函数。这个回调函数是通过函数 ep_ptable_queue_proc 来进行设置的。这个回调函数是干什么的呢?其实,对应的文件描述字上如果有事件发生,就会调用这个函数,比如套接字缓冲区有数据了,就会回调这个函数。这个函数就是 ep_poll_callback。这里你会发现,原来内核设计也是充满了事件回调的原理。
1 | /* |
ep_poll_callback
ep_poll_callback 函数的作用非常重要,它将内核事件真正地和 epoll 对象联系了起来。它又是怎么实现的呢?
首先,通过这个文件的 wait_queue_entry_t 对象找到对应的 epitem 对象,因为 eppoll_entry 对象里保存了 wait_queue_entry_t,根据 wait_queue_entry_t 这个对象的地址就可以简单计算出 eppoll_entry 对象的地址,从而可以获得 epitem 对象的地址。这部分工作在 ep_item_from_wait 函数中完成。一旦获得 epitem 对象,就可以寻迹找到 eventpoll 实例。
1 | /* |
接下来,进行一个加锁操作。
1 | spin_lock_irqsave(&ep->lock, flags); |
下面对发生的事件进行过滤,为什么需要过滤呢?为了性能考虑,ep_insert 向对应监控文件注册的是所有的事件,而实际用户侧订阅的事件未必和内核事件对应。比如,用户向内核订阅了一个套接字的可读事件,在某个时刻套接字的可写事件发生时,并不需要向用户空间传递这个事件。
1 | /* |
接下来,判断是否需要把该事件传递给用户空间。
1 | /* |
如果需要,而且该事件对应的 event_item 不在 eventpoll 对应的已完成队列中,就把它放入该队列,以便将该事件传递给用户空间。
1 | /* If this file is already in the ready list we exit soon */ |
我们知道,当我们调用 epoll_wait 的时候,调用进程被挂起,在内核看来调用进程陷入休眠。如果该 epoll 实例上对应描述字有事件发生,这个休眠进程应该被唤醒,以便及时处理事件。下面的代码就是起这个作用的,wake_up_locked 函数唤醒当前 eventpoll 上的等待进程。
1 | /* |
查找 epoll 实例
epoll_wait 函数首先进行一系列的检查,例如传入的 maxevents 应该大于 0。
1 | /* The maximum number of event must be greater than zero */ |
和前面介绍的 epoll_ctl 一样,通过 epoll 实例找到对应的匿名文件和描述字,并且进行检查和验证。
1 | /* Get the "struct file *" for the eventpoll file */ |
还是通过读取 epoll 实例对应匿名文件的 private_data 得到 eventpoll 实例。
1 | /* |
接下来调用 ep_poll 来完成对应的事件收集并传递到用户空间。
1 | /* Time to fish for events ... */ |
ep_poll
这里 ep_poll 就分别对 timeout 不同值的场景进行了处理。如果大于 0 则产生了一个超时时间,如果等于 0 则立即检查是否有事件发生。
1 | static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events, int maxevents, long timeout) |
接下来尝试获得 eventpoll 上的锁:
1 | spin_lock_irqsave(&ep->lock, flags); |
获得这把锁之后,检查当前是否有事件发生,如果没有,就把当前进程加入到 eventpoll 的等待队列 wq 中,这样做的目的是当事件发生时,ep_poll_callback 函数可以把该等待进程唤醒。
1 | if (!ep_events_available(ep)) { |
紧接着是一个无限循环,这个循环中通过调用 schedule_hrtimeout_range,将当前进程陷入休眠,CPU 时间被调度器调度给其他进程使用,当然,当前进程可能会被唤醒,唤醒的条件包括有以下四种:
- 当前进程超时;
- 当前进程收到一个 signal 信号;
- 某个描述字上有事件发生;
- 当前进程被 CPU 重新调度,进入 for 循环重新判断,如果没有满足前三个条件,就又重新进入休眠
对应的 1、2、3 都会通过 break 跳出循环,直接返回。
1 | //这个循环里,当前进程可能会被唤醒,唤醒的途径包括 |
如果进程从休眠中返回,则将当前进程从 eventpoll 的等待队列中删除,并且设置当前进程为 TASK_RUNNING 状态。
1 | //从休眠中结束,将当前进程从wait队列中删除,设置状态为TASK_RUNNING,接下来进入check_events,来判断是否是有事件发生 |
最后,调用 ep_send_events 将事件拷贝到用户空间。
1 | //ep_send_events将事件拷贝到用户空间 |
ep_send_events
ep_send_events 这个函数会将 ep_send_events_proc 作为回调函数并调用 ep_scan_ready_list 函数,ep_scan_ready_list 函数调用 ep_send_events_proc 对每个已经就绪的事件循环处理。
ep_send_events_proc 循环处理就绪事件时,会再次调用每个文件描述符的 poll 方法,以便确定确实有事件发生。为什么这样做呢?这是为了确定注册的事件在这个时刻还是有效的。
可以看到,尽管 ep_send_events_proc 已经尽可能的考虑周全,使得用户空间获得的事件通知都是真实有效的,但还是有一定的概率,当 ep_send_events_proc 再次调用文件上的 poll 函数之后,用户空间获得的事件通知已经不再有效,这可能是用户空间已经处理掉了,或者其他什么情形。在这种情况下,如果套接字不是非阻塞的,整个进程将会被阻塞,这也是为什么将非阻塞套接字配合 epoll 使用作为最佳实践的原因。
在进行简单的事件掩码校验之后,ep_send_events_proc 将事件结构体拷贝到用户空间需要的数据结构中。这是通过 __put_user 方法完成的。
1 | //这里对一个fd再次进行poll操作,以确认事件 |
ep_poll() 函数主要做以下几件事:
- 判断被监听的文件集合中是否有就绪的文件,如果有就返回。
- 如果没有就把当前进程添加到 epoll 的等待队列中,并且进入睡眠。
- 进程会一直睡眠直到有以下几种情况发生:
1、被监听的文件集合中有就绪的文件
2、设置了超时时间并且超时了
3、接收到信号 - 如果有就绪的文件,那么就调用 ep_send_events() 函数把就绪文件复制到 events 参数中。
- 返回就绪文件的个数。
最后,我们通过一张图来总结 epoll 的原理: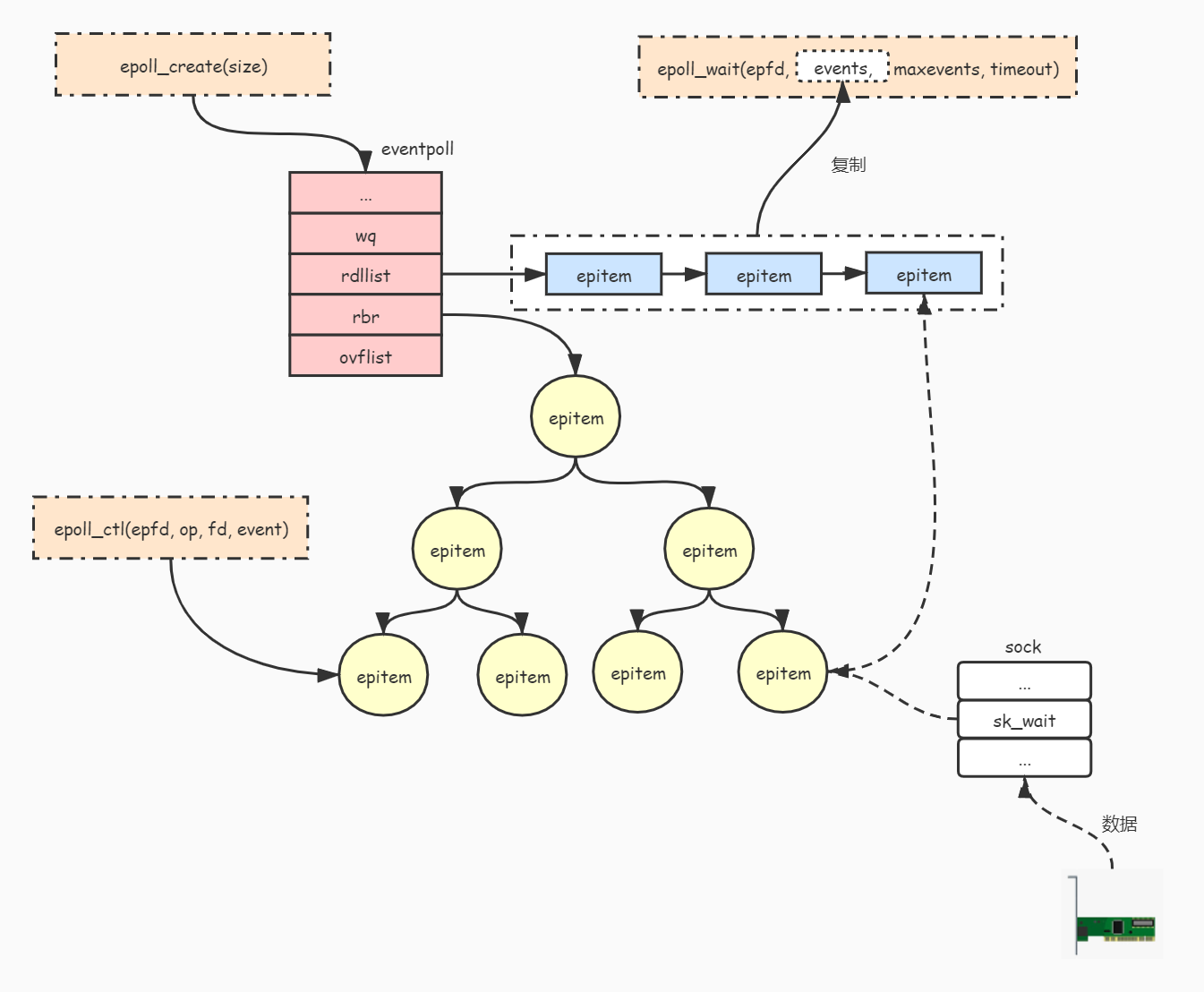
Level-triggered VS Edge-triggered
从实现角度来看其实非常简单,在 ep_send_events_proc 函数的最后,针对 level-triggered 情况,当前的 epoll_item 对象被重新加到 eventpoll 的就绪列表中,这样在下一次 epoll_wait 调用时,这些 epoll_item 对象就会被重新处理。
在前面我们提到,在最终拷贝到用户空间有效事件列表中之前,会调用对应文件的 poll 方法,以确定这个事件是不是依然有效。所以,如果用户空间程序已经处理掉该事件,就不会被再次通知;如果没有处理,意味着该事件依然有效,就会被再次通知。
1 | //这里是Level-triggered的处理,可以看到,在Level-triggered的情况下,这个事件被重新加回到ready list里面 |
epoll VS poll/select
最后,我们从实现角度来说明一下为什么 epoll 的效率要远远高于 poll/select。
首先,poll/select 先将要监听的 fd 从用户空间拷贝到内核空间,然后在内核空间里面进行处理之后,再拷贝给用户空间。这里就涉及到内核空间申请内存,释放内存等等过程,这在大量 fd 情况下,是非常耗时的。而 epoll 维护了一个红黑树,通过对这棵黑红树进行操作,可以避免大量的内存申请和释放的操作,而且查找速度非常快。
下面的代码就是 poll/select 在内核空间申请内存的展示。可以看到 select 是先尝试申请栈上资源,如果需要监听的 fd 比较多, 就会去申请堆空间的资源。
1 | int core_sys_select(int n, fd_set __user *inp, fd_set __user *outp, |
第二,select/poll 从休眠中被唤醒时,如果监听多个 fd,只要其中有一个 fd 有事件发生,内核就会遍历内部的 list 去检查到底是哪一个事件到达,并没有像 epoll 一样,通过 fd 直接关联 eventpoll 对象,快速地把 fd 直接加入到 eventpoll 的就绪列表中。
1 | static int do_select(int n, fd_set_bits *fds, struct timespec64 *end_time) |
四、总结
epoll 流程
1、epoll_create()
从 slab 缓存中创建一个 eventpoll 对象,并且创建一个匿名的 fd 跟 fd 对应的 file 对象,而 eventpoll 对象保存在 struct file 结构的private 指针中,并且返回。该 fd 对应的 file operations 只是实现了 poll 跟 release 操作。
2、创建 eventpoll 对象的初始化操作
获取当前用户信息,是不是 root,最大监听 fd 数目等,并且将这些信息保存到 eventpoll 对象中。然后初始化等待队列,初始化就绪链表,初始化红黑树的头结点。
3、epoll_ctl()
将 epoll_event 结构拷贝到内核空间中,并且判断加入的 fd 是否支持 poll 结构(epoll、poll、select,I/O 多路复用必须支持 poll 操作)。并且从 epfd->file->privatedata 获取 event_poll 对象,根据 op 区分是添加、删除,还是修改,首先在 eventpoll 结构中的红黑树查找是否已经存在了相对应的 fd,没找到就支持插入操作,否则报重复添加的错误。
插入操作时,会创建一个与 fd 对应的 epitem 结构,并且初始化相关成员,比如保存监听的 fd 跟 file 结构之类的。重要的是指定了调用poll_wait 时的回调函数用于数据就绪时唤醒进程。poll_wait 内部初始化设备的等待队列,将该进程注册到等待队列,完成这一步, 我们的 epitem就跟这个 socket 关联起来了,当它有状态变化时,会通过 ep_poll_callback() 来通知。最后调用加入的 fd 的 file operation->poll 函数(最后会调用 poll_wait 操作)用于完成注册操作。最后将 epitem 结构添加到红黑树中。
4、epoll_wait()
计算睡眠时间(如果有),判断 eventpoll 对象的链表是否为空,不为空那就干活不睡眠。并且初始化一个等待队列,把自己挂上去,设置自己的进程状态为可睡眠状态。判断是否有信号到来(有的话直接被中断醒来),如果啥事都没有那就调用 schedule_timeout 进行睡眠,如果超时或者被唤醒,首先从自己初始化的等待队列删除,然后开始拷贝资源给用户空间了。拷贝资源则是先把就绪事件链表转移到中间链表,然后挨个遍历拷贝到用户空间,并且挨个判断其是否为水平触发,是的话再次插入到就绪链表。
epoll 的改进
epoll 维护了一棵红黑树来跟踪所有待检测的文件描述字,红黑树的使用减少了内核和用户空间大量的数据拷贝和内存分配,大大提高了性能。
同时,epoll 维护了一个链表来记录就绪事件,内核在每个文件有事件发生时将自己登记到这个就绪事件列表中,通过内核自身的文件 file-eventpoll 之间的回调和唤醒机制,减少了对内核描述字的遍历,大大加速了事件通知和检测的效率,这也为 level-triggered 和 edge-triggered 的实现带来了便利。
通过对比 poll/select 的实现,我们发现 epoll 确实克服了 poll/select 的种种弊端,不愧是 Linux 下高性能网络编程的皇冠。我们应该感谢 Linux 社区的大神们设计了这么强大的事件分发机制,让我们在 Linux 下可以享受高性能网络服务器带来的种种技术红利。
五、拓展延伸
epoll 实现特点
- 等待队列 waitqueue
队列头 wait_queue_head_t 往往是资源生产者,队列成员 wait_queue_t 往往是资源消费者,当头的资源 ready 后,会逐个执行每个成员指定的回调函数,来通知它们资源已经 ready 了。 - 内核的 poll 机制
1、被 poll 的 fd,必须在实现上支持内核的 poll 技术,比如 fd 是某个字符设备,或者是个 socket,它必须实现 file_operations 中的 poll 操作,给自己分配有一个等待队列头,主动 poll fd 的某个进程必须分配一个等待队列成员, 添加到 fd 的等待待队列里面去,并指定资源 ready 时的回调函数。
2、用 socket 做例子,它必须要实现一个 poll 操作,这个 poll 是发起轮询的代码必须主动调用的,该函数中必须调用 poll_wait(),poll_wait() 会将发起者作为等待队列成员加入到 socket 的等待队列中去,这样 socket 发生状态变化时可以通过队列头逐个通知所有关心它的进程,这一点必须很清楚的理解, 否则会想不明白 epoll 是如何得知 fd 的状态发生变化的。 - epollfd 本身也是个 fd,所以它本身也可以被 epoll,可以猜测一下它是不是可以无限嵌套 epoll 下去…
其他部分内核知识点
- fd 我们知道是文件描述符,在内核态,与之对应的是 struct file 结构,可以看作是内核态的文件描述符。
- spinlock,自旋锁,必须要非常小心使用的锁,尤其是调用 spin_lock_irqsave() 的时候,中断关闭,不会发生进程调度,被保护的资源其它CPU 也无法访问。这个锁是很强力的,所以只能锁一些非常轻量级的操作。
- 引用计数在内核中是非常重要的概念,内核代码里面经常有些 release、free 释放资源的函数几乎不加任何锁,这是因为这些函数往往是在对象的引用计数变成0时被调用,既然没有进程在使用在这些对象,自然也不需要加锁。struct file 是持有引用计数的。
原文链接
参考文章
1、Epoll 实现原理
2、epoll源码分析(基于linux-5.1.4)
3、Linux内核笔记:epoll实现原理(一)
4、epoll内核源码详解+自己总结的流程
- 本文标题:epoll实现原理分析(转载)
- 本文作者:beyondhxl
- 本文链接:https://www.beyondhxl.com/post/2518bc76.html
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!






